生成式AI这一年:从群雄乱战到生态确立,世界已被改变
导读:2022年11月30日,OpenAI的ChatGPT正式上线,从此AI大模型浪潮席卷而来,硅谷创业市场瞬间火爆,风投资本极速转向,二级金融概念股疯狂飙升,科技巨头拉响红色警报,抢夺人类未来的蛋糕争夺战,正式开打。
文|硅谷101
2022年11月30日,OpenAI的ChatGPT正式上线,从此AI大模型浪潮席卷而来,硅谷创业市场瞬间火爆,风投资本极速转向,二级金融概念股疯狂飙升,科技巨头拉响红色警报,抢夺人类未来的蛋糕争夺战,正式开打。
仅仅一年,随着各大资本和巨头入场,AI人工智能的技术迅速发展:从底层大模型,到基础设施,到机器学习操作(MLOps),再到消费端应用,生成式AI的生态已经初步建立,并且将在2024年随着AI的进一步训练和稳定,行业发展会加速向下游移动,人工智能会进一步改变你我的生活,乃至改变整个世界。
这期文章我们给大家梳理了ChatGPT发布一周年的时间线,看看大模型如何改变了这个世界。
OpenAI这一年:愈发庞大和神秘
我们先来看看OpenAI在这一年发生了什么。
2022年11月30日,ChatGPT正式上线
2022 年12月4日,推出 4 天后,用户破百万;两个月后,用户破亿
2023年1月23日,微软向 OpenAI 投资 100 亿美元
2023年2月1日,OpenAI 推出 ChatGPT plus订阅,开启了付费旅程
2023年3月14日,OpenAI 发布 GPT-4,plus 用户可访问
2023年3月23日,ChatGPT Plus 用户可以访问第三方插件和浏览模式(可以访问互联网)
2023年5月18日,OpenAI 推出了 ChatGPT的iOS 应用程序
2023年7月10日,OpenAI 向 ChatGPT Plus 的所有订阅者提供其专有的代码解释器(Code Interpreter)插件
2023年9月25日,OpenAI 宣布 ChatGPT“现在可以看、听、说”。ChatGPT Plus 用户可以上传图像,而移动应用程序用户可以与聊天机器人交谈
2023年10月19日,OpenAI 最新的图像生成模型 DALL-E 3 被集成到 ChatGPT Plus 和 ChatGPT Enterprise 中;该集成使用 ChatGPT 在与用户对话的指导下编写 DALL-E 提示
2023年11月6日,OpenAI举行开发者大会,推出了 GPTs,用户可以自定义自己的GPT,未来甚至还能上传到GPT store
2023年11月17日,Sam Altman被董事会罢免
2023年11月21日晚,Sam Altman回到OpenAI、恢复CEO头衔
正值ChatGPT一周年之际,OpenAI内部上演了连续反转的董事会罢免CEO事件,虽然最终Sam Altman回归公司,但这场风波将OpenAI内部的分裂呈现在了世人面前,而这家公司的内部冲突和信息不透明,让外界对AI的发展充满了疑问和担忧。
比如GPT-5是什么样子的?Q*项目是什么?是什么触发了OpenAI此次的管理层冲突?AGI真的在OpenAI内部达到了吗?ChatGPT一周年,人们对AI发展的问号更多了,而OpenAI并没有变得更透明,而是越来越神秘...

路透社爆料说,在Sam Altman被董事会罢免之前,OpenAI内部的研究人员发送给董事会一封信件,这封信警告称他们发现了一种可能对人类构成威胁的重大人工智能技术,代号为Q*。Q*被一些 OpenAI 的人认为可能通向超级智能或人工通用智能(AGI)的重大突破。研究人员认为它可能对人类构成威胁。
而正巧在不久前的亚太经合组织峰会上,Sam Altman说了以下这段话:
“在 OpenAI 的历史上,现在已经是第四次,最近一次是在过去几周内,我有幸在房间里,当我们推开无知的面纱,将发现的边界向前推进,能够做到这一点是我一生职业上的荣誉。”
然后外界又开始各种猜测Q*是啥?是不是OpenAI内部已经达到AGI了?各种阴谋论,公式,引用,都出现了。
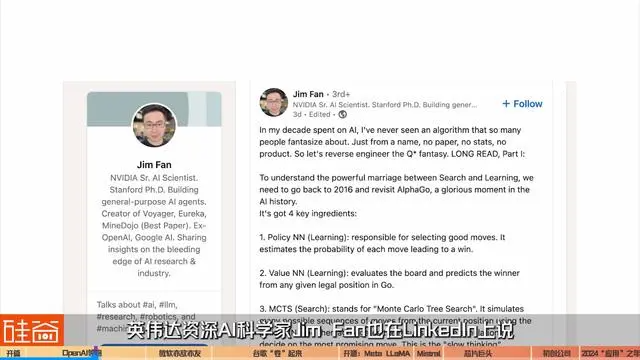
英伟达资深AI科学家Jim Fan也在LinkedIn上说:
“我从未见过一个让这么多人幻想的算法。只是一个名字,没有论文,没有统计数据,没有产品,就开始让我们对 Q* 幻想进行逆向工程。”
但跟硅谷一些资深的AI科学家聊过之后,可能的结论是:并没有传得这么神。
目前我们觉得比较靠谱的猜测是:AI领域有一个技术叫Q-learning,大致的可以理解为自己学习自己。比如说,AlphaGo学习了人类以往的所有棋谱, 然后开始在互联网上和人类棋手下棋。这个时候的AlphaGo围棋的水平相比人类顶尖棋手还只能说得上是有来有回,这也是它打败柯洁和李世石能引起如此轰动的原因。但是人类的棋谱终究是有限的,能陪着AI下棋的人类顶尖棋手也是有限的,想要进步更快就要有更多的对局,更多的棋谱,其中一个办法就是自己和自己下棋。通过自我对弈,AlphaGo Zero在三天内以100比0的战绩战胜了AlphaGo Lee(也就是战胜了李世石的AI版),用40天超越了所有旧版本。
从此以后,人类棋手和AlphaGo的水平天差地别。
我们都知道,GPT-3几乎学习了整个互联网的内容,那么问题来了:人类写的内容学习完了怎么办?能不能AI学习自己生成的内容?也就是说:Q*有可能代表着大模型也可以通过学习自己生成的内容变强了。
当然,这都是外界的猜测,并不是OpenAI官方的解读。但这也是问题所在:OpenAI董事会为什么会罢免Sam Altman?到底什么是触发因素?技术突破到底是什么?Q*是外界过度解读了吗?任凭外界如何谣传如何解读,OpenAI目前也并没有任何官方信息和解释。
在ChatGPT上线一周年之际,OpenAI正变得越来越神秘。而OpenAI也正变得越来越庞大、话语权越来越重要、对资金的追求越来越强势。
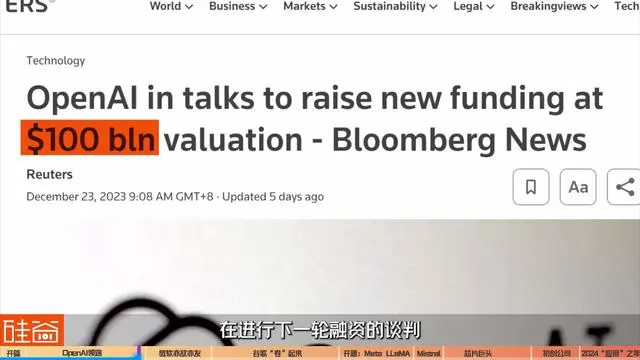
就在2023年圣诞节的前几天新闻爆出:OpenAI正在用1000亿美元的估值在进行下一轮融资的谈判。如果达到这一估值,OpenAI将成为仅次于SpaceX的第二大估值的美国初创独角兽公司。
而在OpenAI快速推进新模型训练、同时推出商业化产品、打造生态之际,巨头们也没有闲着。
微软这一年:亦敌亦友
首先来说说迄今为止的领跑者之一:微软。
ChatGPT火爆全球之后,大家才发现,原来微软才是这背后的大赢家。除了火速向OpenAI追加100亿美元投资、股份占比49%之外,微软动作很快地将GPT运用在自家的应用上。
2023年2月7日微软推出集成了GPT的bing chat,或者叫new bing。发布这些新功能只是第一步,接下来还有无数的调整、优化工作,并且还要采购足够多的服务器支持上亿用户的使用。
而慢慢的,我们开始发现微软和OpenAI之间的关系发生了一点微妙的变化:在Sam Altman的董事会罢免风波期间,微软和CEO纳德拉除了快速稳定局面之外,还将不少OpenAI的客户,特别是大客户群体,转移到了自身平台上,因为通过微软云计算服务Azure,也能调用OpenAI模型,包括ChatGPT,Codex以及DALL-E,还不用担心OpenAI的内斗风险。
张璐,Fusion Fund创始管理合伙人:
在当时发生Sam Altman被罢免的这个周末之内,其实有很多家的初创企业已经直接从OpenAI转向了微软的云服务平台。因为在那边不仅可以用到Azure,他也可以直接去调用OpenAI的模型,在微软平台上.那还有很多的公司就转向了他的竞争对手Anthropic,Anthropic那边他的股权架构、公司架构就简单直接的多。所以我觉得在这样的一个竞争越来越激烈的生态下,市场的一个形态下,虽然OpenAI现在还是有先发优势,有技术优势,但是他竞争对手成长速度也很快,可能留给OpenAI的时间并不多了。
所以,微软和OpenAI的关系,虽然深度绑定,但也各怀异心。
比如说OpenAI与微软的竞争对手Salesforce建立合作,微软也是OpenAI的竞争对手,Meta的开源大模型Llama 2站台成为首发合作伙伴。所以,深度绑定又亦敌亦友的关系,微软和OpenAI在接下来的一年会如何发展,我们拭目以待。
接下来,再来说说另外一个大玩家:谷歌。
谷歌这一年:红色警报下的全力以赴
在ChatGPT出现的时候,市场一片唱衰谷歌的声音,现在依然如此。但谷歌在这一年中,也被迫加快了步伐。
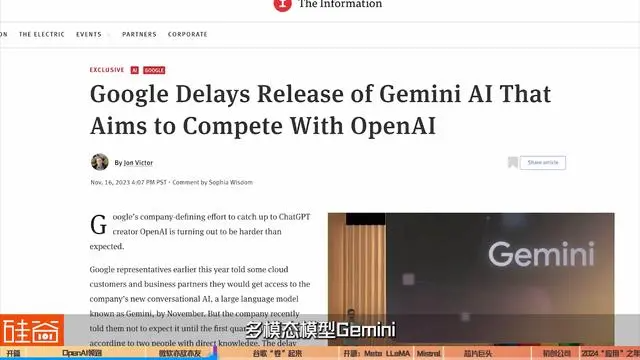
特别是在年底的时候。之前已经有报道说谷歌最被关注的多模态模型Gemini推迟到2024年第一季度,结果,谷歌在12月圣诞节之前哐哐狂发模型,不仅发了Gemini,还发了文生图AI模型Imagen 2,还有,视频生成模型VideoPoet,以及在医疗垂类上也疯狂发力,推出医疗人工智能大模型MedLM等等,红色警报来了之后,谷歌卷起来是真卷。我们接下来用时间轴来回顾一下谷歌的这一年。
2023年2月6日,感受到ChatGPT和微软的压力,Google正式发布聊天机器人Bard。
2月8日,Google举行Bard的新闻发布会,然而,在当天的发布的宣传视频上却犯了错,直接在一个天文问题上给出了错误的答案,市场认为,谷歌在恐慌中将Bard推向市场,一夜之间市值蒸发超过千亿美元。
之后,谷歌决定奋起直追。
2023年3月10日,谷歌推出PaLM-E,史上最大的视觉语言模型,具有 5620 亿个参数,集成了可控制机器人的视觉和语言能力。
2023年5月10日,谷歌推出了3400 亿参数的PaLM 2,来对打GPT-4,号称“在参数量更小的情况下,让模型可以更高效地完成更复杂的任务”。
相比OpenAI,Anthropic,以及其它的开源大模型,谷歌既不是大模型公司,也不打算开源,也就是说,谷歌看中的是模型和自身应用的结合。
比如谷歌在发布会中说:超过25个产品和应用接入了PaLM 2的能力,包括对标微软,以及AI在Gmail、Google Docs、Google Sheets中应用的能力。
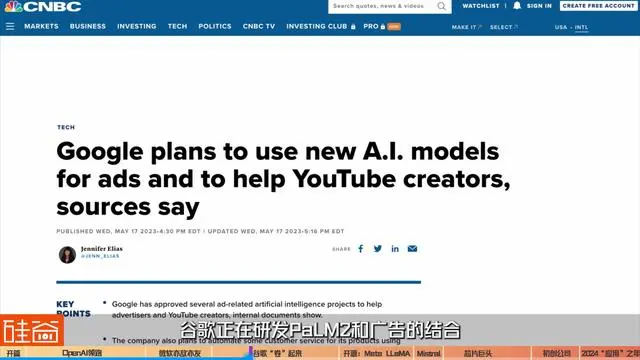
财经媒体CNBC还爆料说:谷歌正在研发PaLM 2和广告的结合,包括允许广告商生成自己的内容和媒体资产,还有对标题和描述等方向的PaLM 2结合,都在测试当中。CNBC这篇爆料显示,AI驱动会在100多种谷歌产品上运行,包括Google Play商店、Gmail、Android搜索和地图等。
年中的时候谷歌还相对安静,但在12月,谷歌突然发力。
2023年12月6日,外界期待已久的谷歌多模态大模型Gemini (双子座)终于发布,包含三个版本:Nano、Pro和Ultra,Pro对标GPT-3.5,Ultra对标OpenAI在今年3月发布的GPT-4,被谷歌CEO Sundar Pichai称为“谷歌迄今为止能力最强的AI模型”,可以处理文本之外的信息,包括图像、视频和音频。从谷歌发布的演示视频中能看出,Gemini结合了视觉和听觉,充分展示出多模态模型的巨大应用潜力。

但是,也正是这段视频,在业内掀起了激烈讨论。谷歌的Gemini演示视频看上去非常流畅、一气呵成,但后来在同步发布的60页报告中,被发现,Gemini结果下面灰色小字标注“CoT@32”,这是什么意思呢?
这代表:Gemini的测试使用了思维链提示技巧、尝试了32次选最好结果,被批评夸大测评成绩、把最好的拍摄结果拼凑在一起,但实际准确度根本达不到。对此,谷歌也直言不讳,承认视频经过后期处理和剪辑。而Gemini到底上线之后能达到什么效果?我们要等到2024年才会有更清楚的认知。
目前谷歌内部已经有多条产品线开始和Gemini融合,或者基于Gemini开始衍生出各种应用的想象,包括一个被称为“埃尔曼计划”(Project Ellmann)的项目,让AI大模型读取用户的照片、搜索历史和生活记忆等数据,创建一个能有birdview“鸟瞰”人们一生数据、全面了解你懂你的AI生活助手。埃尔曼计划团队演示的时候就描述说:“想象一下打开ChatGPT,但它已经知道你生活的一切。你会问它什么?”
与此同时,2023年12月13日,谷歌上线文生图模型Imagen 2:这个文生图的增强模型由Google DeepMind开发。Google 声称与第一代Imagen 相比,Imagen 2在图像质量方面显著提高,并引入了新功能,包括渲染文本,可以用于商业用途和品牌LOGO的生成。通过改变训练数据和方法,Imagen 2能够生成更高分辨率、更美观的图像。
几天之后,在文生图模型之外,谷歌又在12月19日推出了视频生成模型VideoPoet:不仅能根据视频加入音频效果,允许交互编辑,更重要的是,比起其它视频生成应用只能输出2秒左右很短的视频,VideoPoet通过一个讨巧的办法,让AI根据前一个视频的最后一秒接着预测下一秒的内容,来延长了视频生成的长度。
同时,在2023年12月13日谷歌在医疗人工智能大模型上持续发力,推出MedLM。这个模型基于Med-PaLM 2。在2022年,谷歌Med-PaLM模型因为通过了美国医疗执照考试(USMLE)而成为头条新闻,当时的准确率为67%,而今年,Med-PaLM 2进一步将准确率大幅提升至86.5%,根据谷歌的说法,这个分数相当于“专家”医生水平。
谷歌表示,在未来几个月,会将基于Gemini的模型集成到MedLM模型中,以进一步扩展其人工智能功能,未来旨在用于整个医疗保健行业的各个方面,包括医院、药物开发、面向患者的聊天机器人等。例如,美国医疗保健巨头HCA Healthcare正在将MedLM模型用于记录临床医生与患者之间的对话,并将其自动转译为医疗记录,从而提高记录的质量。AI药物发现平台BenchSci正在使用MedLM模型快速筛选大量临床数据并识别某些疾病和生物标志物之间的联系。
而谷歌在年底狂发模型这一点也很有意思,谷歌的新品发布时间大多集中在每年的5月到6月,过去几乎没有在年底的时间段发布过重要产品。而业内有分析认为:这次破例意味着谷歌的管理层担心OpenAI的ChatGPT、微软的Copilot以及其它快速发布迭代的产品正在成为AI领域的代表,谷歌必须加速前进。
开源模型:变酷的Meta小扎和法国Mistral 7B
在OpenAI和谷歌等一众公司闭门造大模型、拒绝开源之际,Meta和扎克伯克反倒在过去这一年,摇身一变,用两个开源模型的发布,再次变得酷了起来。
Meta 在今年2月24日,发布了650亿参数的开源大模型 LLaMA,7 月 12 日发布 700 亿个参数的 LLaMA2。在硅谷背负骂名好多年的Meta突然,成为了率先开源的那一个。
贾扬清,LEPTON.AI创始人:
我们可以发现的一点是说,Meta又变酷了,大家发现说,这很棒。我觉得这个东西对于无论是对于公司的形象,还是比如公司对人才的吸引力,这些都有非常正向的变化,也许并不是马上体现在财报的收入上面。他首先本身长线呢,是一个非常积极正面的形象。我觉得每一个新的领域,其实最重要的一点就是能够让大家玩起来,所以我觉得LLaMA2就相当于是把这个神秘的黑盒子给打开,说你看,大家都可以用了。
Meta在AI上的开源可以说一早就注定了,在我们之前推荐给大家的这本书Genius Makers,中文译本名为《深度学习革命》中有纪录:当年扎克伯格邀请“深度学习”三巨头之一的Yann Lecun加入脸书,为他坐镇AI发展之际,Yann Lecun提的条件就是,在Meta,AI之后的发展必须开源。小扎答应了,于是就有了如今的LLaMa开源路线。而确实在过去一年,LLaMa对创业生态的贡献不容小觑。
事实上,大公司们的“闭源大模型”路线越来越引发外界的不安,越来越多的人站到了“开源派”,认为开源有利于生态的快速建立与发展,也能集结全球的力量,帮助AI模型快速迭代,用群体的智慧去抗衡AI时代集中的垄断。在硅谷,我也独家采访到了超级独角兽公司Databricks的联合创始人Ion Stoica,以及Fusion Fund的创始合伙人张璐,他们都认为,AI开源被寄予厚望。
张璐,Fusion Fund创始管理合伙人:
现在大语言模型的发展,也是有两派,有开源的这一派,也就是现在比较有代表性的LLaMA、LLaMA2,还有包括即将发布的LLaMA3,还包括之前斯坦福出过一个Red Pajama,我当时也很看好这个开源的一个项目。所以我觉得我个人层面上,之所以会看好开源未来的发展,也是基于像The Linux Foundation这样的一个成功的例子,在未来如果说人工智能技术、生成式人工智能,发展到一个阶段,真的开始接近AGI的时候,我们是不是也要去探讨,什么样的公司架构更适合去支持这样的一个技术的应用和去持续的支持这样的一个社群的发展。我觉得The Linux Foundation可以是一个很好的参考的例子。
而硅谷有消息说,Llama 3在2024年早些时候会上线,我们也翘首以盼!
同时,人工智能的开源社区也在迎来更多的大语言模型。这包括Mistral AI,这是一家位于法国的AI初创企业,2023年5月才成立。之后成立7个月就成功完成两轮融资共计4.15亿美元,跨入独角兽行列,如今估值20亿美元。创始人包括CEO 阿瑟·门斯(Arthur Mensch)、首席科学家纪尧姆·兰普尔(Guillaume Lample)和CTO蒂莫西·拉克鲁瓦(Timothée Lacroix)。
门斯曾任谷歌旗下人工智能公司DeepMind的高级研究科学家,积累了优化大型语言模型的宝贵经验;兰普尔和拉克鲁瓦则在Meta人工智能团队共同领导了大型语言模型LlaMa的开发。
2023年9月27日,Mistral AI发布开源大模型Mistral 7B,对标Meta旗下的LLaMa 2,号称仅用73亿个参数,就能表现出更优的性能。对比一下,Meta的LlaMa 2有700亿参数,而OpenAI的GPT 4训练用了1.76万亿个参数。
在2023年年底的时候,Mistral 7B已经风靡硅谷,我身边不少的AI初创企业已经在使用Mistral 7B的模型。所以在2024年,除了少数头部公司继续卷参数更大的模型之外,这样的小参数模型将更有可能会百花齐放,带来更多选择的开源生态。
下一个部分,怎么能忘了芯片大赢家,英伟达呢?
开上游大赢家:芯片巨头们
因为AI发展对算力的需求,英伟达可谓是过去一年的超级超级大赢家,股价在过去一年上涨了超过200%,公司市值过万亿美元。英伟达如何成为AI浪潮中的大赢家可以回看我们之前55分钟超长的英伟达GPU全解析视频。
在时间线上,ChatGPT推出之前,2022年3月22日,英伟达继A100之后发布了H100 GPU,9月21日全面投产。不到半年,ChatGPT发布让英伟达的显卡立马供不应求,官方售价3.5万美元的 H100 成为了绝对的硬通货。
最近,Nvidia再次发力,在2023年11月13 日发布了 H200。与前前一代的NVIDIA A100 相比,容量几乎翻倍,带宽增加 2.4 倍。在处理 Llama2 (一个 700 亿参数的 LLM)等 LLM 时,H200 的推理速度是H100 GPU的近2 倍。
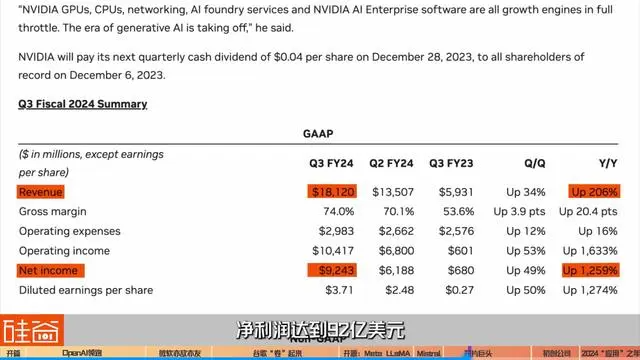
根据英伟达发布的财报,截至今年10月底的一个财报季,英伟达收入达到181亿美元,同比翻番,净利润达到92亿美元,是去年同时期的13倍。
与英伟达的风光无限相比,AMD就落寞很多,因为英伟达垄断了CUDA框架,其他厂商只能被动适配,所以2023年6月13日,AMD发布MI300X GPU的时候,市场对AMD的反应并没有特别强烈,但是硅谷不喜欢垄断者,在英伟达一卡难求之际,AMD不能说没有机会。
在12月6日在硅谷San Jose举办的Advancing AI在线发布会上,AMD将发售MI300系列GPU,包含MI300A与MI300X芯片。目前,微软、Meta、甲骨文、谷歌、亚马逊等公司已经向AMD下了大量订单。而AMD官方预测,MI300芯片将是公司最快达到销售额10亿美元的产品。
此外,值得注意的还有一些过去被我们忽视的势力,比如手机芯片。2023年10月24日,高通发布骁龙8 Gen3处理器;2023年11月6日,联发科发布天玑9300处理器。两款芯片都现场演示了本地运行70亿参数的大模型。
如果高通、联发科的野心是在本地运行大模型的话,云服务厂商也绝对不会甘心为英伟达打工。
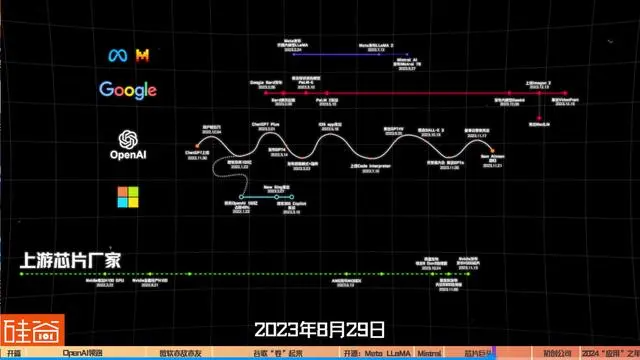
从2016年开始,Google就在自研AI芯片。2023年8月29日,谷歌在Google Cloud Next上发布了第五代TPU v5e,用于大模型训练和推理。
2023年11月15日,在西雅图举行的Ignite开发者大会上,微软推出了自研的AI芯片 Azure Maia 100,可以用于AI大模型的训练和推理。Azure云服务还会用上最新的英伟达H200芯片和AMD的MI300X 芯片,而OpenAI 等用户的AI模型已经开始在MI300X芯片上运行。
2022年11月29日,亚马逊推出基于自研AI芯片Inferentia 2的云服务。而亚马逊AWS在投资OpenAI的竞争对手Anthropic40亿美元之后,也和Anthropic达成了合作关系,成为了Anthropic的主要云提供商,其中亚马逊的Trainium和Inferentia芯片都将在AWS云上被用于训练和部署大模型。
同时,马斯克的芯片研发也在进行。2019年4月23日,特斯拉展示了自研的自动驾驶芯片;2023 年 7 月 20 日特斯拉表示开始生产 Dojo 超级计算机来训练无人驾驶汽车。我有听到特斯拉内部人士说,马斯克对英伟达独占AI GPU市场这件事情大发雷霆,而他不得不买一万张英伟达H100芯片。所以,随着马老板这性格,特斯拉或者xAI的自研AI GPU芯片应该不远了。
但在过去一年,虽然GPU硬件有这么多新闻和玩家涌进来,但云计算大厂研发的这些芯片目前还只是给自己用,来保证自己在AI争夺战中的子弹是充足的。而随着竞争的加剧,我们也希望在新的一年能够看到,GPU和训练成本的下降。
最后,我们再来说说被OpenAI吊打的创业者们。
追不上OpenAI更新的创业者们
在过去一年,硅谷的大模型底层生态似乎已经稳固了下来,大家开始接受大模型就是巨头们的游戏这件事情,VC和创业者们开始寻找巨头们看不上的赛道。然而,这是一件风险极高的事情。
一个绝佳的案例是 Jasper,一个基于GPT-3的AI写文案、从硅谷孵化器YC创业训练营孵化出来的公司。2021年,Jasper收入超4000万美金,到了2022年又翻了一倍达到8000万美元。再然后,ChatGPT发布了,用户们发现,ChatGPT不用付费就能实现一样的效果,于是Jasper的融资马上中断,公司也开始了裁员。
在这轮 AI 浪潮中,你最大的竞争对手不是同行、不是其他公司的创业者、甚至不是自己,而是提供技术服务能力的大模型厂商。
在ChatGPT刚发布的时候,很多人认为 AI 有很多不可解决的问题,比如最早的时候连简单的数学都算不好、比如 ChatGPT 有可能一本正经地胡说八道,它会一本正经地介绍如何做出一道番茄炒篮球。创业项目也都瞄准大模型不能做什么。
只是很多人没想到的是,以上问题都是可以解决的,ChatGPT在最短时间里解决了这些问题。而技术发展的速度超过了想象,比如bing chat集成了 GPT,GPT 可以根据搜索的结果回答问题。
让大家更没想到的是,其实 GPT-4早就训练完成了,只是因为还没有完成对价值观的约束,所以还没有发布。结果等到今年4月发布 GPT-4 的时候,又一次震惊了所有人,因为 GPT-4回答的质量更高,而且GPT-4有着多模态功能,这让一众做多模态的创业公司又被拍在沙滩上。
让这些创业项目无法生存的原因就是:每一代大模型只会更强大,更通用,能做更多事。
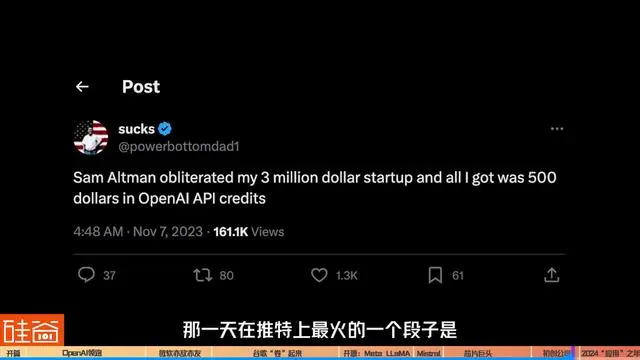
2023年11月6日OpenAI举行开发者大会,那一天最火的一个段子是:
Sam Altman obliterated my 3 million dollar startup and all I got was 500 dollars in OpenAI API credits(Sam Altman 毁掉了我 300 万美元的初创公司,我只得到了 500 美元的 OpenAI API积分)
但并不是说,创业赛道就没有机会了。在硅谷,AI创业热潮依然进行得如火如荼。在OpenAI董事会罢免的第二天,我去到了硅谷一个AI孵化器AGI House的黑客松聚会,里面大约200名创业者和技术人员依然对AI创业充满了热情和信心。同时,风投机构们依然在出手,垂直赛道,基础设置,模型优化等等方向依然是资金涌入的赛道。而业内人士认为,在2024年,更多基于模型的应用将开始进入我们的主流生活。
硅谷101:
在接下来的一年,会发生什么事情?
卫骁,CEO OF REALCHAR:
很多如果纯是为了创业热潮的公司,会“死”不少。尤其是第一波,很早拿到钱,然后什么做不出来的。而且会发生的是说,下面这股创业热潮降下来之后,大家又会回归到重新做产品,就是拿到钱之后,大家就重新进入到开发模式。所以我觉得2024年前半年,会稍微安静一点。但过了一年之后的话,那个时候会有大批量的AI产品出来,真正有用户、有场景、有实际盈利的产品就会出来。
Ion Stoica,DATABRICKS联合创始人:
现在所有的公司都在一窝蜂地做或者使用AI产品,对于一些行业来说可能带来的变化也不是很大,也有一些行业是已经被颠覆了的。但是明显大家都感觉到压力,但凡跟AI沾点边的都去做AI产品了。如果你是做数据库的公司,你也会跑去做AI,即使没有AI基因的,也得开发个Copilot AI助手。我觉得明年开始,我们就能看到哪些工具是能留住用户的了。
而这也许只是ChatGPT火爆全球之后,生成式AI爆发的第一年。一切才刚刚开始,而到达通用人工智能AGI还有很漫长的路要走。