启明创投周志峰:大模型中国创业机会很多
导读:在GTIC 2023中国AIGC创新峰会上,启明创投合伙人周志峰以《AI新浪潮中的创业机会与投资策略》为题发表了主题演讲。

智东西5月18日报道,在GTIC 2023中国AIGC创新峰会上,启明创投合伙人周志峰以《AI新浪潮中的创业机会与投资策略》为题发表了主题演讲。
40多年来,随着算力和数据不断爆发式增长,AI技术形态发生成倍加速变化。周志峰谈道,这波由超大规模预训练模型驱动的AI浪潮,从底层技术展现出变革性的泛化能力和涌现现象,一定程度解决了AI 1.0时代创业面临的不少问题,包括AI算法的训练、数据、推理和具体应用场景过度耦合从而无法规模性落地、缺乏完善的开发基础设施与环境、缺乏上市公司和资本市场估值体系等。
随着大模型和生成式AI浪潮爆发,AI再次成为创业和投资的热点。2020年GPT-3发布的两年内,全球创投机构对AI企业的投资增长了4倍,仅2022年就有13.7亿美元的融资。
与百度创始人李彦宏称“中国基本不会再出一个OpenAI”的观点不同,周志峰认为,中国与美国对于AI通用底座大模型的生态环境非常不同,中国有很多独特的机会。除了高技术壁垒、高人才密度和高资本需求的大模型方向,年轻创业者、垂直产业老兵、AI界大咖在技术和应用多个维度都有不同的创业机会。
启明创投科技团队总结了一张AI新浪潮生态架构及重点布局领域“地图”,从智算平台、工具链、底座大模型、垂类模型、基于第三方模型构建的应用等领域分享了创投参考。
根据启明创投科技团队与100余家2020年后成立的企业的交流统计,在生成式AI创业领域,有14%的创业者聚焦于底层技术,57%的创业者聚焦多模态应用,29%的创业者聚焦语言类应用,能够在AI技术上构建自有壁垒的技术驱动型创业公司和可以融入产业工作流、提供高商业价值的应用型创业公司更容易脱颖而出。
与此同时,他向创企提出了一个发人深省的问题:如果创业公司依赖开源模型或底座大模型API输出的AI能力去做产品,那么当研发底座大模型的企业和科技大厂开始做相同的事,会不会立即赶超创业公司两三年的努力,创业公司的优势是否还能维系?
以下为周志峰的演讲实录:
我将从投资与创业的角度来分享这一次人工智能新浪潮当中有什么样的机会:
第一,我们如何看待这波人工智能新浪潮的生态架构分层,每一层分别有什么样的机会,以及目前中美创业公司使用人工智能技术的三种主要模式。
第二是投资策略,主要分享我们认为的在这波人工智能浪潮中的细分领域投资机会,包括什么样的团队在未来三年中是比较好的创业团队。
01.
反思AI 1.0时代创业瓶颈
预训练大模型带来新变革
现在市场上对这一波人工智能(AI)新浪潮的定义很多,我眼中的AI新浪潮是从2018年基于Transformer的预训练大模型开始的。
到今天AI不知不觉已经发展了七、八十年,四代底层技术架构变革催动了四波AI大机会,每一波浪潮更新迭代更快,用40年走完第一波小规模专家知识,用20年走完第二波浅层机器学习,用8-10年走完一波深度学习,并取得一定的成就,现在是基于大规模预训练模型的深度学习的新篇章。
我们投资AI,主要秉持多年方法论 - 预判趋势,提前布局。在上一波深度学习发展期间,我们在2010年看到了深度学习神经网络的一些进展。2012年问世的AlexNet是一个大的奇点信号,之后我们在2013年投资了专注智能语音的云知声,2014年投资了专注机器视觉的旷视科技,2015年投资了专注机器人的优必选,2016年投资了自动驾驶公司文远智行等。2016年迎来了AlphaGo引发的AI市场热潮。
同样在大规模预训练模型的发展中,我们在2018年观察到一些很明显的信号和重大突破,所以在2022年11月OpenAI发布的ChatGPT引爆市场之前,我们在两年前已经提前完成了一些项目的投资,包括中国的大型预训练模型公司智谱AI、前京东技术委员会主席周伯文创立的衔远科技、前蚂蚁金服副总裁、AI团队负责人漆远创立的无限光年等,预判了大模型的发展趋势。
关于大规模预训练模型带来的变革,很多专家都讲了技术、应用层面,我从投资创业层面分享一下。
我觉得最大的区别还是在深度学习前10年左右时间,即2010-2018年,数据、模型、任务是紧耦合的,AI模型需针对每个特定任务用特定数据去训练特定的算法。
大家觉得人脸识别应用好像都差不多,比如商业楼宇的人脸识别门机闸口、到酒店前台的人脸识别身份证比对,到公安系统智慧城市侦缉用的人脸识别。上面说的几个细分场景,看起来差不多,但即使在一个公司一个团队,使用数据集、训练模型、部署模型的时候,是几件不同的事。
这表明了前一代深度学习的一个大问题——需要特别明确的任务去跟模型数据做强耦合。
这就解释了为什么过去10年,我们一提深度学习做得好的公司,还是科技大厂或是旷视科技、商汤科技等AI独角兽企业,因为那一代人工智能对人才要求非常高,因为数据、模型、场景、任务是强耦合的,这就意味着只有很少一部分人能够完成模型算法调优,做得比其他团队更好。
这也是AI 1.0时代带给创投市场一些反省。那一代人工智能也曾经很热闹,投入那么多钱,非常多的人出来创业,为什么到今天依然没有看到AI赋能万业的大规模落地,而还是在过去五六年那些耳熟能详的场景?核心其实是底层技术的问题。
这一代大规模预训练模型即AI 2.0有比较强的泛化能力,经海量通用数据训练出的底座模型可以直接被下游的各种任务使用。去落地、赋能万业的时候,AI 2.0就更能彰显实力。这也是今天无论投资人、创业者还是科技大厂都对这一代AI释放出这么强烈的信心和热情的核心逻辑。
大规模预训练模型还具有效果好的特点。这么多大厂都展示了AI的能力,核心还是2018年后在In-Context Learning(上下文本学习)、Supervised Fine Tuning监督精调等模型训练技术上的巨大突破。
AI从1950年开始,核心做的是感知、推理、决策。过去几代AI都在感知、判断和决策上有一些突破,唯独欠缺中间的推理。今天,大规模预训练模型把推理能力提升了一个台阶,所有才有生成式AI等新的机会。
当然,涌现现象也是最近提的很多的一个类似玄学的概念。到底为什么大模型这么厉害?因为当训练量超过600亿参数之后会有智能的涌现。
我跟OpenAI、谷歌大脑和国内大模型团队在聊,只要有一天我们还在讲涌现现象,就说明我们今天还没有透彻了解大模型背后真正的机制。
02.
拆解AI创业4大难题
预训练大模型解决了哪些?
之前2010-2018年的AI创业像经历了一次过山车,起来又落下了,核心有4个原因。我们看看这4个原因是否在今天的新浪潮中得到部分解决。
第一,不是产品、缺乏定位,得到了部分解决。
上一波AI基于深度学习小模型,最大的问题是,它只是一项技术。那时候我们期待AI能够成为一个行业,就像我们把百度、阿里、腾讯称作互联网行业的巨头一样,我们期待AI技术变成一个新行业。
但是过去八年,AI没有变成一个行业,我们今天很难称某家公司是一家AI公司。原因就是AI技术虽然取得很大突破,但是放到产品场景中,它只是一个巨大产品中的很小的一个技术组件,并没有把整个产品、整个场景变成颠覆性的新东西。
这是过去AI存在的问题。近年的ChatGPT、GPT-4、Stable Diffusion、DALL·E 2等模型,在诞生的第一天,不光给出了大模型,还给出了几十个使用参考案例,起码让我们看到了这些模型、算法能够用在什么场景,是在向产品化的方向去发展,这是跟之前的AI最大的区别。
过去AI技术应用到哪个领域、做什么任务,需要专家来定义。例如做无人驾驶公司,需要非常有经验的人,去想视觉算法能用在无人驾驶的具体什么功能上;今天可能一个普通人看到GPT-4,脑子里就可以冒出来三、四个使用场景,想到这个技术能做哪些事。
第二点,对技术的合理预期,没有得到很好解决。
创业者仍对技术创新带来的效果提升有着更乐观的估计,但给客户的承诺往往无法实现,低估了客户业务的复杂度,高估了模型的效果和迭代速度,大量AI产品仍然缺乏明确的效果评估指标。
我试用了ChatGPT、GPT-4、谷歌的BERT、百度的文心一言、微软的New Bing等,确实还有很多跟我的预期有差距的地方,这需要在座的很多从业者继续努力,让这波AI更上一个台阶。毕竟在这次浪潮中我们才刚刚开始,还有很长的路要走。
第三点是缺乏配套基础设施,基本解决了。
上一代AI中,百度、谷歌都发布了自研的深度学习框架、训练平台。但是你想想从1980年PC时代到今天,有几万、几十万种帮开发者做从底层操作系统层面到应用层面开发的各种工具软件。而上一代深度学习发展了十年,能想到的还是那几个框架,没有完善的基础设施,帮助开发者去更容易的开发AI应用。
这次不一样,大厂也好,大模型公司也好,给应用公司的就是一个基础设施,应用公司可以在上面构建应用,一下子把AI技术构建应用的难度降低了很多。
应用公司可以根据AI大模型公司提供的API快速构建应用,甚至快速试错更换方向,也不需要招募大量AI工程师进行底层模型的研发,有小规模融资就能快速拉起团队创业。
第四点,缺乏上市公司参考,得到部分解决。
上一代AI过了2017年后,大家都很迷茫。之前更多是早期投资人出于情怀、对技术大趋势的信仰进行投资,投资以后没有资本市场对标,美国也没有出现太多大型AI创业公司,资本市场不知道应该怎么去估值、怎么后续投资,造成了那一波AI高开低走。
但到今天,有一批AI公司跑出来了,在二级市场公开发行股票,登陆了科创板或港交所,起码为一级市场的创业公司和投资机构提供了AI公司的估值参考体系。我相信这会对这一代AI的创业公司未来五年的发展是有利的,起码大家知道你应该值多少钱、你需要融多少钱。
03.
AI再成创业和投资热点
2022年融资达13.7亿美元
上一波AI中,从2012年AlexNet等深度学习技术的突破促使AI成为创业和投资热潮到2015年,融资数量曲线在往上走。2016年3月8号AlphaGo战胜围棋圣手李世石,真正让大众注意到了深度学习和AI。但是2016年、2017年总融资额和新创立的AI企业的数量开始往下走,原因是之前很多AI企业在产业落地上没有交出让市场满意的答卷。
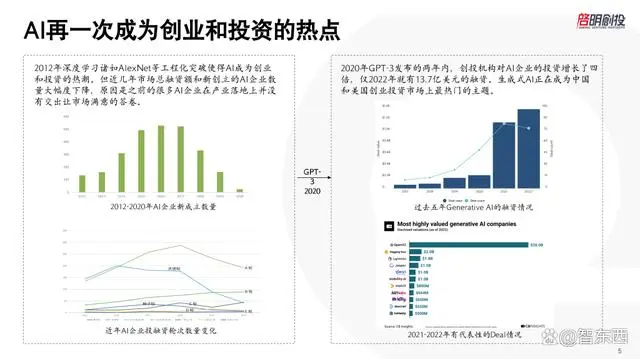
所以我特别希望这一波AI发展不要重蹈覆辙。2022年11月ChatGPT引爆大众热情。这几个月,每周都有新的生成式AI产品发布。我希望不会看到像上一波浪潮一样,大众热情引爆的那一天就是这个行业的最高点,之后行业往下走。我个人对技术底层比较有信心,我认为AI 2.0应该是一直往上走。
可以看到2017年后,种子轮、天使轮、A轮投资都在往下走,说明资本市场在那时候对的AI的信心已经疲软了,创业者也不愿意出来创业做AI公司了,所以基本上2016年到了顶点,往后就越来越少。
2020年OpenAI的GPT-3模型的参数从15亿发展到了1750亿,预训练数据从几GB变成45TB。在美国硅谷,AI重新变成了创业投资中最火爆的一个细分领域,也有很多公司融到了很多钱。GPT-3发布的两年内,创投机构对Al企业的投资增长了4倍,仅2022年就有13.7亿美元的融资。
04.
解读AI新浪潮生态架构:
投资热点与重点布局
这是我们总结的今天AI新浪潮的生态架构图,分成三层:基础架构层、模型层、应用层。红色是一些我们投资的相关公司的例子。
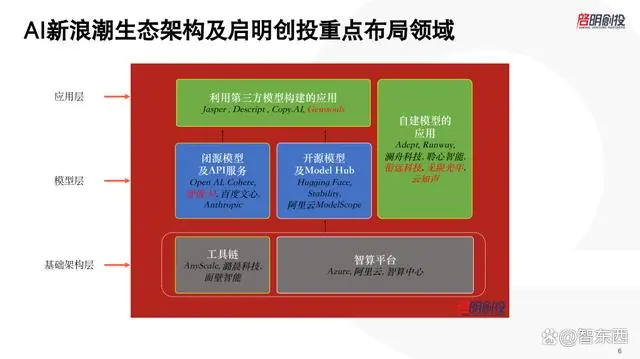
基础架构层中,右边的智算平台是提供算力,智算平台再往下一层是新一代AI芯片,包括我们投资的壁仞科技做通用GPU;左边是工具链,我们认为会有很多新的投资机会。
今天,大模型在训练成本、训练效率、部署效率、管理方便性等方面都有很多问题,毕竟我们才开始两三年,需要大量改善。我们看到中美有越来越多的在以前深度学习十年中积累的训练和推理的经验,去提供软硬件方案,做模型训练和推理的优化,因此工具链方面还会有很多机会。
第二层最关键的模型层,现在看到三种模式。
左边是大家最了解的,对外提供通用底座模型,无论是提供API服务还是帮某个客户、产业去提供定制化模型,不会把模型训练的细节、架构公开,只是对外输出能力。
OpenAI、Cohere、Anthropic,还有国内创企,包括我们投资的智谱AI等等,这一类公司想做的是把AI能力变成水电直接向外输出。
到底是不是像百度创始人李彦宏说的这一块没有创业机会?可以继续思考,我抱有一些不同的意见。我觉得中国和美国的大模型生态不一样,在美国,可能没有更多的创业公司做底座大模型的机会,但在中国我认为还是有机会。
可以看到,除了大家知道的王慧文、王小川、李开复等产业领军者以外,还有一些过去十年的深度学习顶级技术团队正在打造新一代的底座大模型,我觉得都很值得期待。
中间是开源模型及Model Hub。国外的Hugging Face已经做得非常好,还有Stability,阿里云也有ModelScope开源社区。我觉得中国在这一块没有什么创业机会,开源社区这种文化跟中国的创业环境也不是非常契合,更多是科技大厂或者一些国外的社区去做。
最右边是在大模型以外还有一些做自建垂类模型的垂直应用,从拥有垂直行业的特有数据、到训练模型、到开发终端应用,端到端去做,是面对一个行业甚至一个大场景的特定模型。我相信,虽然今天大模型的类似于涌现机制等还没有完全被搞清楚,但是针对某一个场景、用一些非常高质量的数据做一些闭环训练的模型,最终基于这个模型开发出应用,一定是有一些机会的。
如我们投资的周伯文创办的衔远科技,专门针对零售业打造的模型;我们投资的原蚂蚁金服副总裁漆远创办的无限光年和云知声,在医疗领域去打造的行业大模型,这些都是非常值得关注的一种模式。
最上面的应用层,90%的公司没有自己去做模型,更多是调用大模型的API去做应用。具体这些创业公司怎么使用这些模型?我把它简单地归为三类,大家可以判断哪类更符合自己的创业模式或者投资逻辑,我觉得没有哪个更高级或者更好。
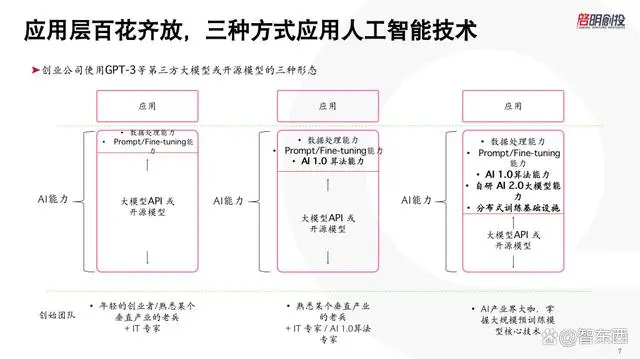
第一种是其使用的90%的AI能力不属于自己研发, 要么是调用像OpenAI、百度这样一些对外输出的大模型能力,要么是拿像Stable Diffusion之类的开源模型做一些修改,团队本身通常不会有很强的预训练模型开发能力,更多是具备应用层的能力,能够配置一些技术人员去调用API或开源模型,做一些自己的修改与精调,只要拥有数据处理团队或做Prompt/Fine-tuning能力的工程团队就可以了,工程团队规模可能在10至20个人左右。
我们看到无论在中国还是在硅谷,创业团队有很鲜明的特点,基本是比较年轻的,或者是上一代互联网老兵出来创业,或者是某些非常懂某个垂类行业的人出来创业。
第二种是创业团队完成了一个更复杂的AI产品,70%~80%是调用大模型API或使用开源模型,但又要涉及到一些大模型以外的AI算法,比如做一个虚拟人,可能用OpenAI的GPT-4生成了文本,但还要用生成对抗算法GAN去做虚拟人的换脸,则内部要培养一些深度学习算法工程师,才能去完成公司的完成的应用。
第三种是从头开始训练一个行业大模型,不仅在预训练大模型的架构、并行计算基础设施、数据处理上都要有自研团队,甚至要解决大家经常说的至少有1024张A100 GPU的算力问题。
在这方面,中美都有一些AI产业界大咖出来创业,基本上当年都是科技大厂的C-level或者副总裁,以前在大模型领域有一定的经验,可能创始团队都很豪华,天使融资就是亿元人民币以上,需要融资十亿元以上才能对外交付产品。
这是我们看到的三种模式,背后的团队和研发AI技术的方式是非常不同的。
05.
生成式AI创业浪潮汹涌
多模态应用最热
这是我们过去两年半看过的100多家与大模型、生成式AI相关的中国团队,不算那些旧瓶装新酒的、在看到大模型机会后才切换过来的团队。
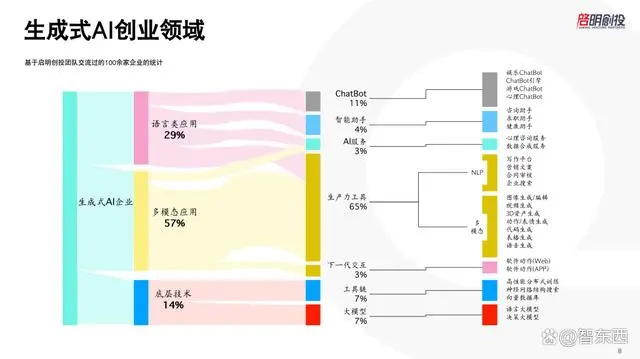
这些在过去两年半时间内成立的100多家生成式AI新公司中,将近30%做语言类应用;最多的是做多模态应用的公司,占比57%;还有一些做底层大模型或是大模型基础架构优化的,占14%。
具体方向中,ChatBot占11%,生产力工具占的最多,高达65%,包括文案写作、脚本生成、虚拟人物、视频广告生成等等。
这类我只强调一点,大家需要思考一个问题:我们如果还处在这一代AI浪潮的较早期阶段,做这样一个产品,并且依赖的主要AI能力是来自一些开源大模型或底座大模型API的能力,那么大厂如果把你做的东西变成它的大模型上的一个小feature(功能),它会不会比你做得还要好?你创业两、三年的这些努力,会不会只在大厂加一个feature(功能)的动作下,就失去意义了?如果做得太薄,创业公司肯定会面临大模型企业的挑战。
(峰会前)过去几天,我每天都是凌晨四、五点就会醒,每天都可以看到一些硅谷科技大厂发布新产品。
凌晨四、五点醒了以后,我就去排队申请谷歌的Bard、Adobe的Firefly,Saleforce的Einstein AI等的试用账号。许多科技大厂一直都在研发生成式AI技术,又有多年场景、产品、和用户的积累,只要加一个feature(功能),可能比创业公司100多人做了两、三年的产品还要好,创业是不是就比较危险?这是值得思考的问题。
确实看到大量的团队在做这个领域,但是这些领域一定是科技大厂会用生成式AI技术去自我迭代的领域。
06.
结语:真正颠覆性的应用,也许还在路上
我来峰会之前,问了一下GPT-4:生成式AI处于什么发展阶段?
它的回答正好跟我的个人思考差不多。之前有人说我们现在正处于90年代初刚产生Lynx、Mosaic浏览器的互联网时代,基础设施还没有搭好,谈应用太早,现在的应用公司都不会是互联网最后走向大众市场后成为巨头的腾讯、谷歌、和Facebook。也有人说不对,基础架构已经搭成了,现在就是出现新的谷歌、新的腾讯、新的Facebook、即应用爆发的阶段。
我个人认为生成式AI更像互联网90年中后期的阶段,基础架构还没有特别成熟,但是大家看到了基础架构迭代的方向,正在拼命努力,也会像当年互联网出现亚马逊那样的早期能够最直接的展现新一代技术能力的应用企业。这些能力已经被一些创业者看到了,他们正在做些像互联网早期的应用尝试。
但我也觉得,真正更颠覆互联网的应用可能在亚马逊诞生之后几年后才会出现,生成式AI领域往后的道路也还很漫长。
最后,迈向通用人工智能大方向,我们现在还是起始阶段,刚刚起步。
所以无论您是创业者还是投资人,都不用特别焦虑,因为这些天实在信息量太大了,我觉得真正颠覆性的、改变人类的应用,也许还在路上,还有几年才能到来。
我们多看看、多想想、多去用第一性原理思考,之后再去创业、再去投资布局,其实也不晚。
谢谢大家!
以上是周志峰演讲内容的完整整理。