国产GPU,谁能突破算力封锁,推动中国AI高速发展?
导读:提供了全球高端人工智能大半算力的英伟达CEO黄仁勋,为何在此次大会中将ChatGPT带来的变化称为“人工智能的iPhone时刻”?在“人工智能的iPhone时刻”背后,又是哪些基础硬件设施与相关的企业支撑着AI行业不断前行呢?
文|奇偶派
近日,英伟达在美国加州总部举办了面向软件开发者的年度技术峰会GTC。在会上,英伟达创始人黄仁勋披露了最新人工智能相关的软硬件技术,并在演说中将“AI的iPhone时刻”这句话重复强调了三遍。
事实上,英伟达与AI可谓是缘分不浅,截至目前,英伟达的GPU芯片正在为全球绝大多数的人工智能系统提供最基础的算力支持,而ChatGPT母公司OpenAI,便是凭借着10000片英伟达的GPU芯片,成功训练出了GPT-3大语言模型,震惊了全世界。
那么,提供了全球高端人工智能大半算力的英伟达CEO黄仁勋,为何在此次大会中将ChatGPT带来的变化称为“人工智能的iPhone时刻”?在“人工智能的iPhone时刻”背后,又是哪些基础硬件设施与相关的企业支撑着AI行业不断前行呢?
本文将以英伟达发布会为切入点,介绍国内GPU行业相关企业的发展现状,进而讲述为何算力缺乏的原因,以期为读者展现GPU行业的现状与未来发展。
大秀肌肉的英伟达与火种初现的中国厂商
作为全球算力硬件当之无愧的龙头公司,英伟达每年的GTC大会都吸引着众多尖端科技工作者的目光,尤其是在2023这个ChatGPT的出圈元年,作为人工智能硬件的主要提供商,英伟达GTC的曝光量更是得到了显著的增加。
而在此次大会中,英伟达展示了其针对训练、推理、云服务等多维度的ChatGPT领域布局。
在AI训练领域,英伟达助力算力持续提升,赋能大模型突破。
基于GPU并行计算的特性以及英伟达在AI领域的前瞻布局,英伟达在AI训练领域拥有绝对优势,同时十分重视人工智能赛道,不断提升其人工智能硬件的计算能力。
并且,随着GPT大模型对于算力需求的提升,全球科技巨头均已开始或即将搭载英伟达的H100产品:Meta已在内部为团队部署了基于H100的Grand Teton AI超级计算机;OpenAI将在其Azure超级计算机上使用H100来为其持续的AI研究提供动力。
而在此次GTC 2023上,基于Hopper架构及其内置Transformer Engine,英伟达H100针对生成式AI、大型语言模型(LLM)和推荐系统的开发、训练和部署都进行了优化,利用FP8精度在LLM上提供较上一代A100更快的训练及推理速度,助力简化AI开发。
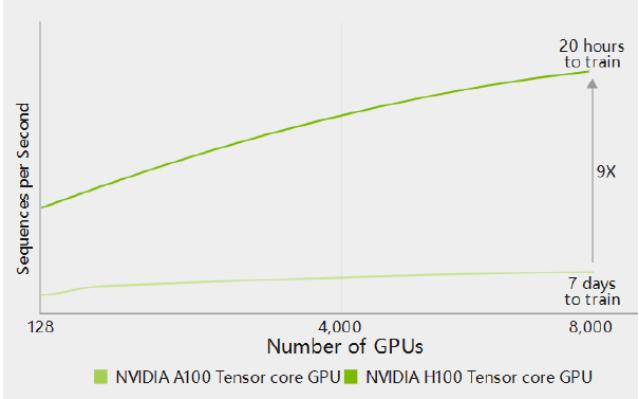
图源:英伟达公司官网,中金公司研究部
而在AI推理领域,AI视频、图像生成、大型语言模型部署及推荐系统也在加速部署。
在今年的GTC 2023中,英伟达推出了全新的GPU推理平台:基于加速AI视频、图像生成、大型语言模型部署和推荐系统,形成了4种配置、1个体系架构和1个软件栈的产品体系。
其中H100 NVL GPU受到了市场较为广泛的关注:英伟达在GTC 2023公开表示,该产品将配备双GPU NVLink,或将实现比现用A100快10倍的速度,可处理拥有1750亿参数的GPT-3大模型,并支持商用PCIe服务器扩展,适用于训练大型语言模型。
黄仁勋称,相较于目前唯一可以实时处理ChatGPT的HGX A100,一台搭载四对H100和双NVLink的标准服务器能将速度提升10倍,并且还可以将大语言模型的处理成本降低一个数量级。黄仁勋也将NVIDIA DGX H100称作全球客户构建AI基础设施的蓝图。
黄仁勋也表示,ChatGPT仅仅是人工智能第一个出圈的应用,也只是一个起点。在人工智能浪潮来临之时,全球范围内必将出现一批进军人工智能大模型硬件的企业。但英伟达在短期内拥有绝对的技术优势,未来也将持续发力。
毫无疑问,英伟达发布的最新硬件对于人工智能企业来说,是解决算力问题的最大福音,但对于中国企业来说,这却并非是一则喜讯。
2022年8月,美国监管机构以国家安全为由,对NVIDIA A100、H100两款GPU实施禁令,不得销售给中国企业,意在通过“卡脖子”的方法来降低国内AI模型的传输速度,拖延中国人工智能发展。
从长远来看,未来大模型的研发和部署是必然趋势,而每个大模型训练和部署的背后,都有几万个 GPU 芯片在支持。因此,未来随着这方面的研发和应用的普及,通用 GPU 市场需求将会迎来爆发式增长。
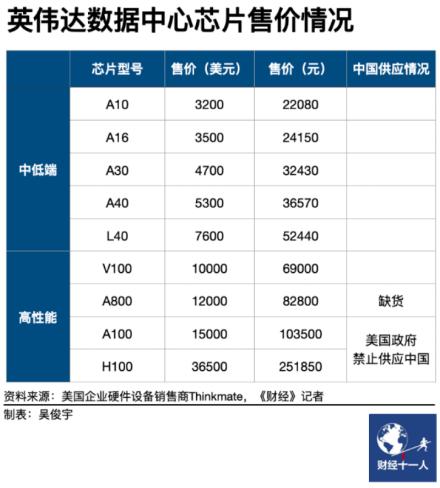
而中国能获得的最佳替代品,则是英伟达专供中国的A800芯片,也是A100的“阉割版”,其传输速度只有A100的70%,而在H100大规模供货后,中美AI公司的差距则将进一步拉大。
高性能的GPU,已经成为了限制中国AI行业发展的最直接因素之一。
但也正是在算力需求激增、硬件供给被切断、难以真正“市场化”的背景下,国内才涌现了一批GPU的“火种”企业。
这些新兴的企业中,核心团队基本都是业内顶尖专家,许多技术专家来自英伟达、AMD 等国际龙头企业。初创企业们接连完成新融资,并陆续推出新品加速商业化。
首先,是借军工信息化之风迈向全面国产替代的GPU企业——景嘉微。
景嘉微的技术核心团队来自于国防科技大学,公司业务也是依靠军工业务图形显控模块芯片起家,持续投入研发布局全自主研发GPU芯片的图形显控传统业务。
在后续的发展中,伴随着国家专项基金的支持与企业芯片研发的推进,公司的GPU芯片业务逐渐“开枝散叶”,渗透入了民用市场,在“8+N”个行业中进行着快速的发展。
截止目前,公司是国内首家成功研制国产GPU芯片并实现大规模工程应用的企业,也是国内唯一具备完全自主研发GPU能力并产业化的上市公司,目前已拥有267项专利,在图形显控领域走在行业前列。
而公司的产品,也正在从“能用”迈向“好用”的阶段。
根据景嘉微2021年公告,公司研发的JM9系列图形处理芯片将支持OpenGL 4.0、HDMI 2.0等接口,以及H.265/4K 60-fps 视频解码。其核心频率至少为1.5GHz,配备8GB显存,浮点性能约 1.5 TFlops,与英伟达GeForce GTX 1050 相近。
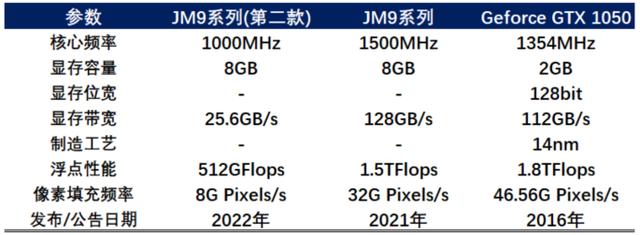
资料来源:中关村在线,芯参数,Nvidia 官网,公司公告,太平洋证券研究院
而在与公司的交流中,相关人员表示,之前的7系列分为多个版本,根据客户的需求、价格和价位承受能力来配合出货,所以取得了较大的成功。而9系目前还在谈价的过程中,也相信9系列会促使全球显卡价格的下行。
并且对方还表示,公司对标的是海外竞争对手几年前的产品,而当利润低于一定程度后,海外的公司会主动放弃市场。公司也会从相对的低端做起,随着技术的进步,逐渐追赶英特尔、AMD的步伐。
尽管目前景嘉微的产品与国际尖端GPU存在着极大的差距,但作为一颗由中国企业完全独立研发、采用正向设计、具有自主知识产权的GPU,已经迈出了国产自主道路上的一大步,成为中国算力的“希望之火”。
接着,是依靠CPU、DCU双轮驱动,深度受益国产化替代的企业——海光信息。
海光信息成立于2014年,主营业务为研发、设计和销售应用于服务器、工作站等计算、存储设备中的高端处理器,目前拥有海光通用处理器(CPU)和海光协处理器(DCU)两条产品线。
而其中,DCU作为专注通用计算、单纯提供人工智能算力的产品,成为了企业新的业绩增长极。
海光信息于2018年切入DCU领域,坚持自主研发,目前已经成功掌握高端协处理器微结构设计等核心技术,并以此为基础推出了性能优异的DCU产品,具备强大的计算能力和高速并行数据处理能力,性能基本能与国际同类型主流产品同台竞技。
选取公司深算一号产品和国际领先的GPU厂商英伟达的高端GPU产品(A100)及AMD高端GPU产品(MI100)进行对比,在典型应用场景下,海光信息深算一号单颗芯片的指标基本达到国际上同类型高端产品的水平。
对标目前国际主流人工智能企业都在使用的NVIDIA A100产品,海光DCU单芯片产品基本能达到其70%的性能水平,同时,公司DCU产品的片间互联性能还有较大的提升空间。
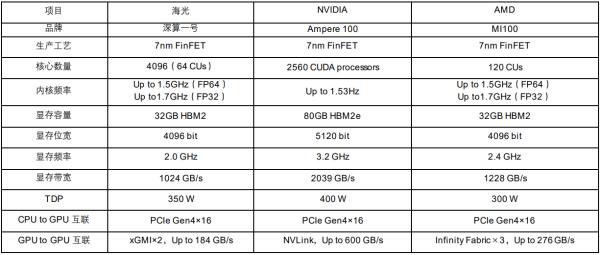
资料来源:公司招股说明书、平安证券研究所
而在硬件之外,海光信息也为打破CUDA生态专门制作了软件配置:海光 DCU 协处理器全面兼容 ROCm GPU计算生态,由于ROCm与CUDA的高度相似性,CUDA用户可以以较低代价快速迁移至 ROCm平台,因此,海光DCU协处理器能够较好地适配、适应国际主流商业计算软件和人工智能软件,软硬件生态丰富。
此外,海光还积极参与开源软件项目,加快了DCU产品的推广速度,并成功实现了与GPGPU主流开发平台的兼容。
近些年来,在国内诸多创企的努力下,GPU硬件的突破捷报频传,但目前我国CPU厂商距离英伟达等国际头部厂商的距离仍然还有很远。
所以对于中国GPU企业来说,做好国产的Plan B,再谋求发展,或许才是正确的方向。
但可以确定的是,随着科技的进步,中国GPU算力行业一定要、也一定会摆脱被“卡脖子”的问题,让中国的AI企业用上中国的GPU,打赢这场算力之战。
算力,为何如此紧缺?
上文谈到了英伟达的算力“肌肉”展示与国产CPU的奋起直追,那么,当前人工智能企业的算力需求究竟几何?为何“AI芯片”第一股英伟达,能在短短不到四个月的时间内,股价暴涨83%?
从算力需求端来看,人工智能模型的参数量随换代呈现着指数型增长的态势。
以GPT-3.5为例,作为一种大型语言模型,有着海量的参数。即使OpenAI目前没有公布ChatGPT所使用的 GPT-3.5 的相关数据,但由图可得,随着新模型的推出,参数量需求呈现翻倍式增长。
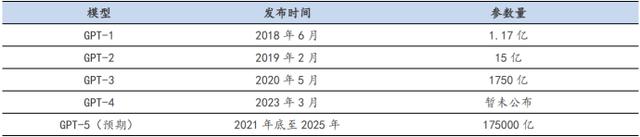
资料来源:OpenAI 官网,安信证券研究中心
而在参数量的增加之外,ChatGPT的下一代GPT-4还可以通过多模态来拓展应用场景。
GPT-4作为一个多模态大模型(接受图像和文本输入,生成文本),相比GPT-3.5可以更准确地解决难题,具有更广泛的常识和解决问题的能力,文本处理能力更是达到了ChatGPT上限的8倍。
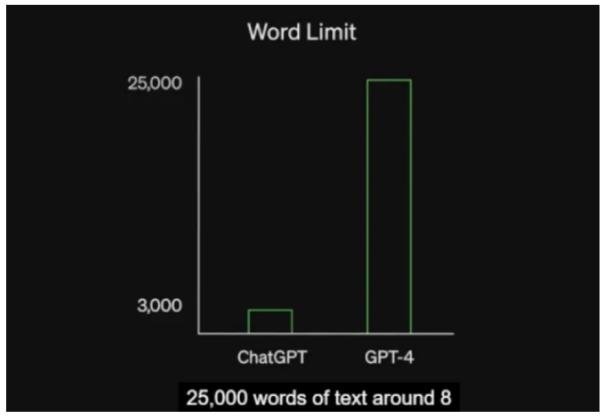
数据来源:OpenAI《GPT-4 Technical Report》,广发证券发展研究中心
不过,伴随着人工智能的成熟而增长的,自然是其背后的算力需求:OpenAI预计,人工智能科学研究要想取得突破,所需要消耗的计算资源每3~4个月就要翻一倍,所以出现了算力需求爆炸式增加的情况。
而在人工智能企业需求大幅增长的情况下,算力的供给却逐步放慢了脚步。
在半导体行业中,一直有着这样一种说法:“当价格不变时,集成电路上可容纳的元器件的数目,约每隔18-24个月便会增加一倍,性能也将提升一倍。换言之,每一美元所能买到的电脑性能,将每隔18-24个月翻一倍以上。这一定律揭示了信息技术进步的速度。”
这就是我们所熟知的摩尔定律,实际上,大家身边最直观的感受便是每大概两年左右,你的电脑或手机就要面临淘汰的境地了,尤其是当今的智能手机,基本主流配置的手机,2年就得准备换新了。
但是,伴随着半导体制程的持续演进,短沟道效应以及量子隧穿效应带来的漏电、发热等问题愈发严重,追求经济效能的摩尔定律已经日趋放缓,甚至接近失效。
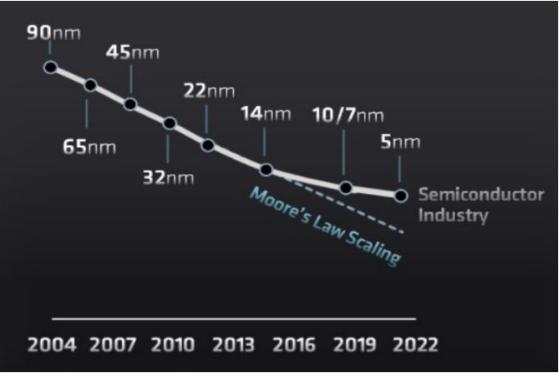
也就是说,哪怕在需求不变的情况下,算力基础设施就已经该走上增加数量的赛道了,更何况算力需求正在以指数爆炸的速度增长。
因此, AI 模型训练算力需求增长与摩尔定律出现了极不匹配的现象,这势必推动对算力基础设施需求的快速增长,而这,也是英伟达等众多GPU硬件企业被资金追捧的根本原因——他们手中握着开启AI时代的金钥匙。
写在最后
或许正如黄仁勋所说,“人工智能的iPhone时刻”已经来临,走向下一个时代的路,早就摆在了世人面前。
但是众多最尖端的人工智能企业,还在为AI时代的“入场券”而发愁犯难,高昂的算力价格、永远缺货的高端GPU,成为了企业最大的软肋。
由此可见,对于未来的数字经济而言,算力等基础设施的舞台将会成为AI企业们甚至国家之间的第一个角力场。正如全球著名投资机构a16z评价ChatGPT时所说,“基础设施服务商可能才是最大赢家,获得最多的财富。”
包括AI在内的新技术在取得突破后,要想走入“寻常百姓家”,实现大规模的部署和应用,算力的安全、高速、高可靠、高性能等能力缺一不可。甚至可以说,算力的增强真正驱动了数字经济的增长。
而对于中国企业来说,短期的封锁或许是困境,但从另外一个角度来想也未必不是机遇,以景嘉微、海光信息为代表的的中国高算企业,也必将在层层封锁中杀出,以卓越的产品,推动中国滚滚的数字化大潮!