牛津大学研究人员创建有史以来最大的人类家谱
导读:来自牛津大学大数据研究所的研究人员在绘制人类的全部遗传关系图方面迈出了重要的一步:一个可以追溯我们所有人的祖先的单一家谱。
来自牛津大学大数据研究所的研究人员在绘制人类的全部遗传关系图方面迈出了重要的一步:一个可以追溯我们所有人的祖先的单一家谱。这项研究周四已经发表在《科学》杂志上。
-
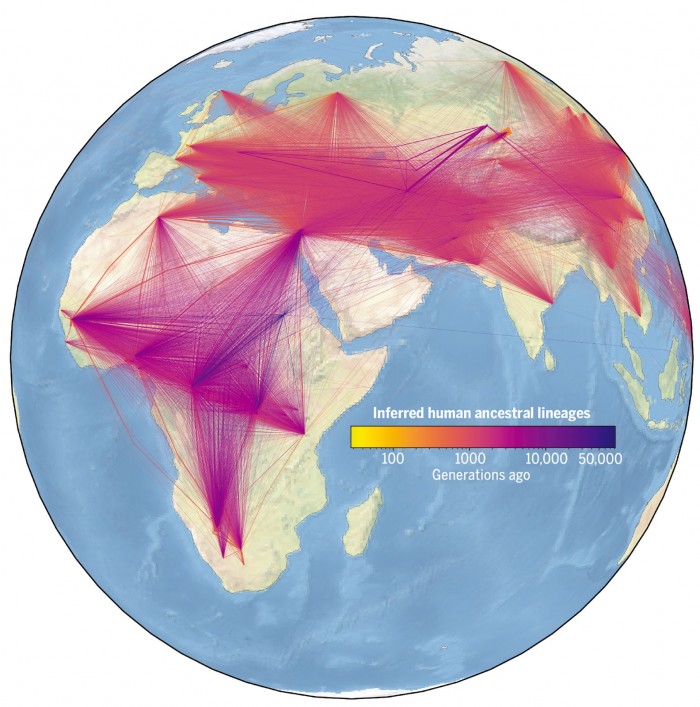
人类遗传多样性的新谱系网络以前所未有的细节揭示了世界各地的个体之间的关系。
-
该研究预测了共同的祖先,包括他们生活的大概时间和地点。
-
该分析恢复了人类进化史上的关键事件,包括从非洲迁移出来的事件。
-
该基本方法可在医学研究中得到广泛的应用,例如确定疾病风险的遗传预测因素。
过去二十年来,人类基因研究取得了非凡的进展,产生了数十万人的基因组数据,包括来自成千上万的史前人类。这带来了一种令人兴奋的可能性,即追踪人类遗传多样性的起源,以产生一个完整的关于世界各地的个人如何相互关联的地图。
到目前为止,这一愿景的主要挑战是找出一种方法来结合来自许多不同数据库的基因组序列,并开发出处理这种规模数据的算法。然而,牛津大学大数据研究所的研究人员周四发表的一种新方法可以很容易地结合来自多个来源的数据,并可扩展到容纳数百万的基因组序列。
大数据研究所的进化遗传学家,主要作者之一黄燕(音译)博士解释说:“我们基本上建立了一个巨大的家谱,一个全人类的家谱,尽可能准确地模拟产生我们今天在人类中发现的所有遗传变异的历史。这个家谱使我们能够看到每个人的基因序列与其他每个人的关系,沿着基因组的所有点。”
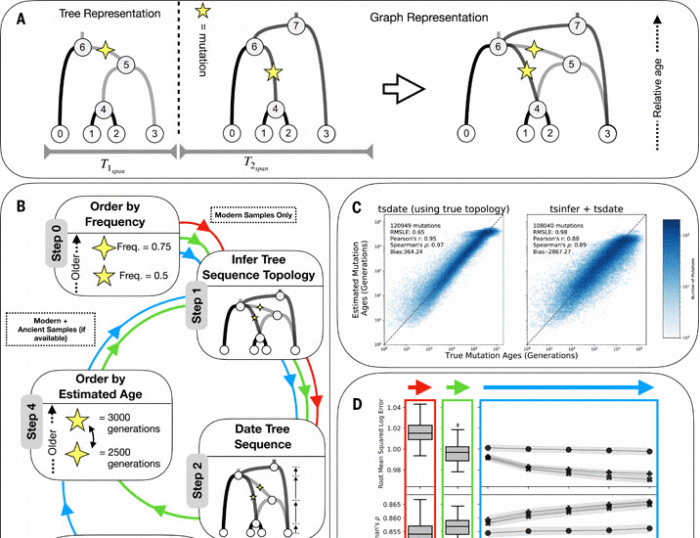
由于单个基因组区域只从父母一方,即母亲或父亲那里继承,基因组上每个点的祖先可以被认为是“一棵树”。这组“树”被称为 “树序列”或“祖先重组图”,它将基因区域通过时间追溯到遗传变异首次出现的祖先。
主要作者Anthony Wilder Wohns博士,作为他在大数据研究所的博士学位的一部分进行了这项研究,现在是麻省理工学院和哈佛大学的Broad研究所的博士后研究员。他说:“从本质上讲,我们正在重建我们祖先的基因组,并利用它们形成一个庞大的关系网络。然后我们可以估计这些祖先生活的时间和地点。我们的方法的力量在于,它对基础数据的假设很少,而且还可以包括现代和古代的DNA样本。”
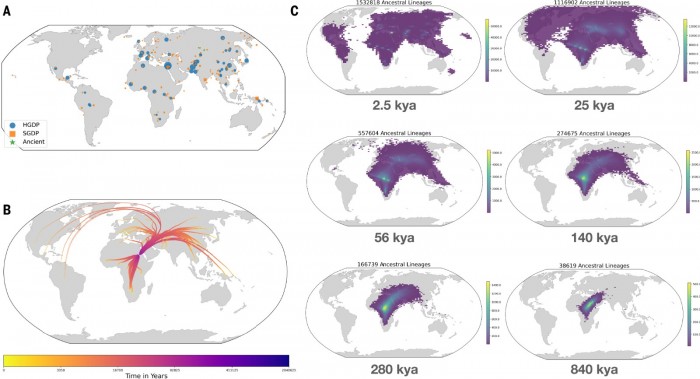
该研究整合了来自八个不同数据库的现代和古代人类基因组数据,并包括了来自215个人口的总共3609个个体基因组序列。古代基因组包括在世界各地发现的样本,年龄从1000年到超过10万年不等。该算法预测了进化树中必须存在的共同祖先的位置,以解释遗传变异的模式。结果网络包含了近2700万个祖先。
在添加了这些样本基因组的位置数据后,作者使用该网络来估计预测的共同祖先的居住地。结果成功地重现了人类进化史上的关键事件,包括从非洲迁移出来。
尽管谱系图已经是一个极其丰富的资源,但研究小组计划通过继续纳入可用的遗传数据使其变得更加全面。由于“树序列”以一种高效的方式存储数据,该数据集可以很容易地容纳数百万的额外基因组。
黄燕表示:“这项研究为下一代的DNA测序奠定了基础。随着现代和古代DNA样本的基因组序列质量的提高,这些‘树’将变得更加精确,我们最终将能够生成一个单一的、统一的地图,解释我们今天看到的所有人类遗传变异的后裔。”
Wohns博士补充说:“虽然人类是这项研究的重点,但该方法对大多数生物都有效;从猩猩到细菌。它在医学遗传学方面可能特别有益,可以将遗传区域和疾病之间的真正联系从我们共同的祖先历史中产生的虚假联系中分离出来。”