华为拿什么破解AI核心难题?
导读:众所周知,作为AI的后入局者,面对 AI 算力需求的爆发式增长,华为大胆地提出要为业界提供“易获取、用得起、方便用”的算力。如今,距离AI战略提出一年,华为是否已经找到算力破局的入口?
OpenAI近期发布的研究显示,仅2012年以来,人们对于算力的需求增长六年就超过30万倍,平均每年增长10倍,远远超过了摩尔定律的发展速度。
众所周知,作为AI的后入局者,面对 AI 算力需求的爆发式增长,华为大胆地提出要为业界提供“易获取、用得起、方便用”的算力。如今,距离AI战略提出一年,华为是否已经找到算力破局的入口?
这也是即将到来的2019华为全联接大会备受瞩目的重要原因。
17世纪后期,英国采矿业,特别是煤矿,已发展到相当的规模,单靠人力、畜力已难以满足排除矿井地下水的要求,而现场又有丰富而廉价的煤作为燃料。现实的需要促使人们致力于“以火力提水”的探索。1769年英国人詹姆斯·瓦特制造了蒸汽机,引起了18世纪的第一次工业革命。
100年后,美国人发明和实现了电力的广泛使用,引领了19世纪的第二次工业革命。
1946年,世界第一台二进制计算机的发明,人类在20世纪进入了第三次工业革命,信息技术的发展尤其是移动互联网的普及极大地改变了人类的生活。
进入21世纪,人类正在迎来以智能技术为代表的第四次工业革命,人工智能、物联网、5G以及生物工程等新技术融入到人类社会方方面面;驱动全球宏观趋势的变化,如社会可持续发展,经济增长的新动能,智慧城市、产业数字化转型、消费体验等。

第四次工业革命的人工智能将引领人类进入新纪元
人工智能是一系列新的通用目的技术(GPT),包括自然语言处理、图片识别、视频分析等。人工智能是信息化进程的新高度,信息技术带来了效率的提升,人工智能则带来生产成本的变化。行业+AI,人工智能将会改变每个行业、每个职业、每个组织、每个家庭和每个人。
第四次工业革命的人工智能将引领人类进入新纪元
时代又仿佛回到了对采矿行业非生物动力需求极大的17世纪。进入21世纪,人工智能也对算力提出了强劲的增长需求,按照 OpenAI 最新的分析,从2012年到2018年,最大的人工智能训练运行中使用的算力增长了30多万倍,每3.5个月就会翻倍,远远超过了摩尔定律的增长速度(每 18 个月芯片的性能翻一倍)。AI算力需求的急剧增长与传统CPU算力缓慢提升(每年10%)之间存在巨大矛盾,全球掀起造芯运动,加速算力成本降低和AI应用普及。
人工智能的三个方面算力(工业云计算和边缘计算)、数据(工业大数据)和算法(工业人工智能),在中国,基于人口规模和经济的发展程度,在数据和行业应用都在全球处于领先地位。但是AI算力资源却很稀缺而且昂贵,各行业应用需要越来越强劲的AI算力。算力价格贵、使用难和资源难获取是目前AI发展的三大瓶颈:
Ø价格贵:现在人工智能整个训练的过程,譬如训练人脸识别、交通综合治理、自动驾驶,模型的训练成本非常高昂的。
Ø使用难:缺乏一个统一的开发框架,无法适配从训练到推理,从公有云到私有云、边缘、终端的多种应用场景,开发、调优、部署的工作量巨大。
Ø难获取:业界用于AI计算的GPU供货周期长,限量供应等,导致硬件资源不易获取。
业界开发大规模AI训练芯片的主要厂家,比如英伟达、Google和华为都推出了自己的AI训练芯片。英伟达Tesla V100 GPU最高提供125 TeraFLOPS深度学习性能,最大功耗为300瓦特。Google I/O 2018开发者大会上,Google 推出了第三代 TPU 3.0,最高提供90 TeraFLOPS深度学习性能。华为在2018年10月的全联接大会上发布了针对AI训练场景的昇腾昇腾910 AI处理器。昇腾910 AI处理器,是当前计算密度最大的单芯片,适用于AI训练,可提供256 TeraFLOPS的算力,最大功耗为310瓦特。
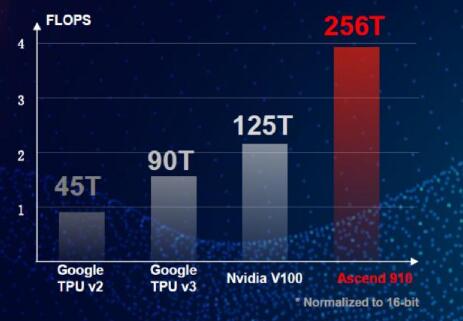
业界主流AI训练芯片能力对比
面向人工智能这个大的时代潮流,算力的稀缺和昂贵在一定程度上制约了当前的人工智能发展。华为认为,易获取、用得起、方便用的算力,是AI产业发展的关键。
华为数十年长期聚焦在ICT基础设施研发和建设领域,深刻理解运营商和企业用户的使用场景,以“高起点”和“全栈全场景”入局AI领域,真正提供普惠的、强大的算力。
华为昇腾系列AI处理器,采用了面向张量计算的达芬奇3D Cube架构,该架构面向AI的全新突破性设计,为昇腾AI处理器提供了超强的AI算力,使得芯片具有高算力、高能效、可扩展的优点。
基于统一的达芬奇架构,华为可以支持Ascend-Nano、Ascend-Tiny、Ascend-Lite、Ascend-Mini、Ascend-Max等芯片规格,具备从几十毫瓦IP到几百瓦芯片的平滑扩展,天然覆盖了端、边、云的全场景部署的能力。“达芬奇架构可大可小,从Nano一直到Max、从穿戴设备一直到云,可以全场景覆盖;我们推出MindSpore的目的就是协同达芬奇架构来面向全场景的。也就是说,在端、边缘、云都可以训练和推理,还可以进行相互协同,这是现在其他的计算框架所做不到的。” 华为轮值董事长徐直军表示。
AI训练的耗时跟模型的复杂度、数据集和硬件资源的配置是强相关的,在天文研究、自动驾驶训练、气象预测、石油勘探等大规模训练时,硬件资源尤其显得重要,人工智能的快速发展,得益于硬件和云计算技术的提升,更得益于各个行业数字化带来的大量的数据来训练模型。开发平台要求从原始数据到标注数据、训练数据、算法、模型、推理服务,实现千万级模型、数据集以及服务对象的全生命周期的管理。
同时,无智能不成云,全栈发展走向纵深,AI已经成为云的基础业务,实现云端训练和推理。在云上部署,支持在线和批量的推理,满足大规模并发的复杂场景需求。云、AI、IoT协调使能蓝海市场,在智慧家庭、物联网和车联网等场景,构建云+AI+IoT的综合解决方案,开拓新的人工智能市场。
华为的AI战略包括投资基础研究,在计算视觉、自然语言处理、决策推理等领域构筑数据高效(更少的数据需求) 、能耗高效(更低的算力和能耗),安全可信、自动自治的机器学习基础能力;打造全栈方案,面向云、边缘和端等全场景的、独立的以及协同的、全栈解决方案,提供充裕的、经济的算力资源,简单易用、高效率、全流程的AI平台。
华为全球产业展望(GIV)报告显示,全球数据量将从2018年32.5ZB快速增长到2025年的180ZB。对于企业,AI算力需求每三个月增长一倍,AI应用率到2025年将达80%。不难发现,在算力领域已取得突破的华为,站在了一个巨大的时代风口之上。