李国杰院士谈超算与智能历史性会合:“70年未有之大变局”
导读:超级计算机正“变成”智能计算机、人们也在为人工智能研制专用超算。不过,要弄清楚前因后果,这篇李国杰院士关于智能计算和超算的分析值得一看。
开篇先送两个黑人问号:
What?超级计算机不是智能计算机?
Really?人工智能不适合用超算?
上边两个问题的答案其实都似是而非——事实是,超级计算机正“变成”智能计算机、人们也在为人工智能研制专用超算。不过,要弄清楚前因后果,这篇李国杰院士关于智能计算和超算的分析值得一看。
6月27日~29日,此前5届都在美国召开的世界智能计算机大会(BenchCouncil)今年首次来到中国举办。在这次大会上,中国工程院院士、中科院计算所首席科学家、中科曙光董事长李国杰用了半个多小时的时间,以《对智能超级计算机的几点认识》为题,深入浅出地剖析了“智能计算机”的历史、现在和未来。

李院士自1987年回国后带领团队一手打造了曙光系列高性能计算机,并创办曙光公司。今年,他已经76岁了。和75岁的任正非一样,李老时至今日仍为中国计算机事业殚精竭虑。他经常提到自己写的一句诗:“我事从来万般险,自古瓜儿苦后甜。”这给当下的中国很多启示。
“智能计算机”是李国杰院士从美国留学回来一直从事的工作,他关于超算和智能计算的分析,专业、权威,面面俱到。闻道有先后,笔者聆训之后不忍自专,特整理如下,现学现卖,以飨读者。
0.0 精彩提要 0.0
“计算机之父”冯•诺伊曼在给“控制论之父”诺伯特·维纳的信中说了什么?
钱学森先生关于计算机的什么预测竟与历史发展高度吻合?
李国杰院士口中所说的“70年未有之大变局”究竟是什么?
不卖关子,下面进入正题。
历史:超算是超算,智能是智能
“智能计算现在很热,但是从1936年开始这个话题就一直被探讨。”
“冯•诺伊曼曾试图模仿神经网络设计计算机,但是发现这条路走不通。”
“钱学森先生对计算机发展之路预测得很准,超算是超算,智能是智能。”
在第三次人工智能浪潮兴起之前,超算是超算,智能是智能。
我们通俗说的计算机一般指数字计算机。智能计算则不同,人们一直希望“智能计算机”能像人脑一样处理信息,这是一种模拟计算。
计算机发展史上,数字计算与模拟神经网络经历了分分合合。“计算机之父”冯•诺伊曼曾经试图模仿神经网络设计计算机。1946年11月,冯•诺伊曼在给“控制论之父”诺伯特·维纳的信中写道:“我们选择了太阳底下最复杂的一个对象……向世人展示了一种绝对的且无望的通用性。”
事实上,从第一台电子计算机开始,计算机的发展就与模拟神经网络分道扬镳。此后,集成电路的发明及其后来几十年在摩尔定律引导下的狂奔,使得用计算机实现人工智能的方式与人脑的思维机制几乎不沾边。
20世纪80年代末、90年代初,在野心勃勃的日本第五代计算机项目带动下,全球掀起一阵“智能计算机热”。当时的热点是面向智能语言和知识处理的计算机,研究重点是并行逻辑推理。
日本五代机走的是“定制化路线”。和日本不一样,我国“智能计算机”研制走的是比较通用的路线:从芯片、系统到软件、应用,都是“非定制化”。
1990年,国家科委(科技部的前身)批准成立“国家智能计算机研究开发中心”(依托中科院计算所),智能中心不但开展了曙光系列并行计算机的研制,还从事了人工智能的基础研究和应用研究,为今天智能超算的发展打下了基础。
当年智能中心的理论研究班吸引了众多AI方向的年轻学者。中科曙光、科大讯飞、汉王等公司的建立和发展都与智能中心有一定关系。寒武纪芯片的研制则继承了智能中心算法与系统结构研究相结合的传统。
钱学森先生曾发表《关于“第五代计算机”的问题》的文章,就智能计算机与超级计算机的发展发表意见。钱老在文章里说:“第五代计算机是什么?是第二代巨型计算机。我认为再把这个概念叫做五代计算机或者六代计算机,就不那么合适了,因为它不是一个计算机了,而是一个智能机,所以建议为了不要混淆起见,就干脆叫第一代智能机。”

钱老关于第五代计算机的建议。来源:李院士PPT
以此为标志,所谓的第五代计算机就分成了两个叉:一个是第二代巨型计算机,一个是第一代智能机——这是两个不同的概念。
事实证明,历史的发展与钱老的预测是相符的,从20世纪80年代以后的30年,计算机的发展之路确实符合钱学森的预测,超算是超算,智能是智能。
现在:智能与超算的历史性会合
“在没有找到变革性的智能平台之前,超级计算是研究和应用人工智能必不可少的基础设施。”
“深度学习等智能应用需要算得特别快的计算机,智能与超算近几年出现了历史性的汇合。”
“人类可能会发明新的智能计算机,但至少最近20年内,智能超算是要高度重视的研究方向。”
超级计算是“算得快”的计算机。但智能计算机和超算不一样:智能的本意是“算得巧”,而不是“算得快”。这是两股道上的车。
超级计算机或高性能计算机是指区别于个人电脑(PC)与低档服务器的计算机。拜最新一期的全球超算TOP500榜单所赐,如今我们可以把世界顶级的超级计算机(高性能计算机)圈定在Pflops 级(千万亿次浮点计算每秒)计算机水平。
本世纪以来,深度神经网络的成功和大数据的兴起,使得超级计算和计算智能(深度学习)走到一起,出现“历史性的汇合”。
这不难理解:以深度学习为标志的第三波人工智能研究需要极强的计算能力。过去高性能计算机主要用于科学计算,现在的高性能计算机已大量用于大数据和机器学习。
一组数据可以说明这一点:2015年,中国HPC在数据分析与机器学习领域应用只有27%,至2016年达到48%、2017年提升到56%。预计这个比例今后还将继续提高。
实际上,智能计算机有许多种类,包括云端(数据中心)智能计算机、智能工作站、人机交互的智能终端和智能物端设备等。今天我们所说的“智能超算”,主要是指云端的巨型智能计算,也就是“面向智能应用的超级计算机”。
但是也应该看到,目前大量采用的智能计算实际上是基于GPU或GPU-Like加速器的“准智能计算”。比如,图像和语音的信号处理计算还是数值计算。
也就是说,现在的神经网络计算仍是数字计算,将来可能用模拟计算——这是智能计算很重要的方向。
智能算法可以加速传统的科学计算。举个例子,今年4月,200多名科研人员从四大洲8个观测点“捕获”了黑洞的视觉证据。此项研究历时10余年,加州理工学院曾经采用Blue Waters超级计算机进行近900个黑洞合并的模拟,花费了2万小时的计算时间。后来采用新的机器学习程序和算法,从模拟中学习,帮助创建新的模型,在毫秒内就能给出合并结束状态的答案,大大加速了关于黑洞的研究。

给黑洞“拍照片”使用了机器学习算法。来源:ESO
如今,机器学习不仅是人工智能领域研究的重点,也正成为整个计算机科学研究的热点。
2018年图灵奖得主约翰·霍普菲尔德提出,计算机科学的发展可以分三个阶段:早期研究主要是开发程度语言、编译技术、操作系统以及研究支撑它们的数学理论,中期重点是研究算法和数据结构,第三阶段的重点已从离散类数学转到机器学习,机器学习成为计算机科学的核心。
未来:智能超算的十大关注方向
“未来智能计算机的核心特征:人脑级能效。”
“摩尔定律走不通了,以后主要是靠结构改进——这是一个黄金时代。”
“未来大多数计算将在专用加速器上完成,而通用处理器将变成配角。”
人类可能会发明新的智能计算机,但至少最近20年内,智能超算是要高度重视的研究方向。关于智能超算的未来研究方向,以下10个方面值得重视。
第一,未来十年是体系结构的黄金时期。
近几十年计算机的飞速发展一半来自摩尔定律,另一半来自系统结构的改进。摩尔定律即将走到尽头(集成电路制造的特征尺寸接近物理极限),计算机未来的改进将主要从结构改进入手。所以说未来十年是“体系结构的黄金时期”。
另外一个角度,就计算机而言,结构越复杂,算法就可以越简单——人类大脑的结构就非常复杂,因此智能化程度很高。所以,未来人工智能需要的不仅仅是计算能力,还需要更复杂的硬件结构。
图灵奖得主、计算机体系结构宗师David Patterson 与John Hennessy 预言:“下一个十年将出现一个全新计算机架构的寒武纪大爆发,学术界和工业界计算机架构师将迎来一个激动人心的时代。”机不可失,时不我待。未来十年应该有像IBM 360和RISC一样重大的体系结构发明,中国学者应该做出不愧于时代的贡献。
第二,“人脑级能效”将是未来智能计算机的核心特征。
人脑智能给发展计算机的启发在于,大脑以20w的功耗实现了10 POPs神经元突触的操作。从目前的发展来看,超级计算机现在的能效还满足不了需求。“超算能效增长远远低于速度增长”,目前我们面临计算机发展70年未有之大变局。这给我们提出挑战,未来超级计算机要达到像人脑一样的能效层次(POPs/W)。
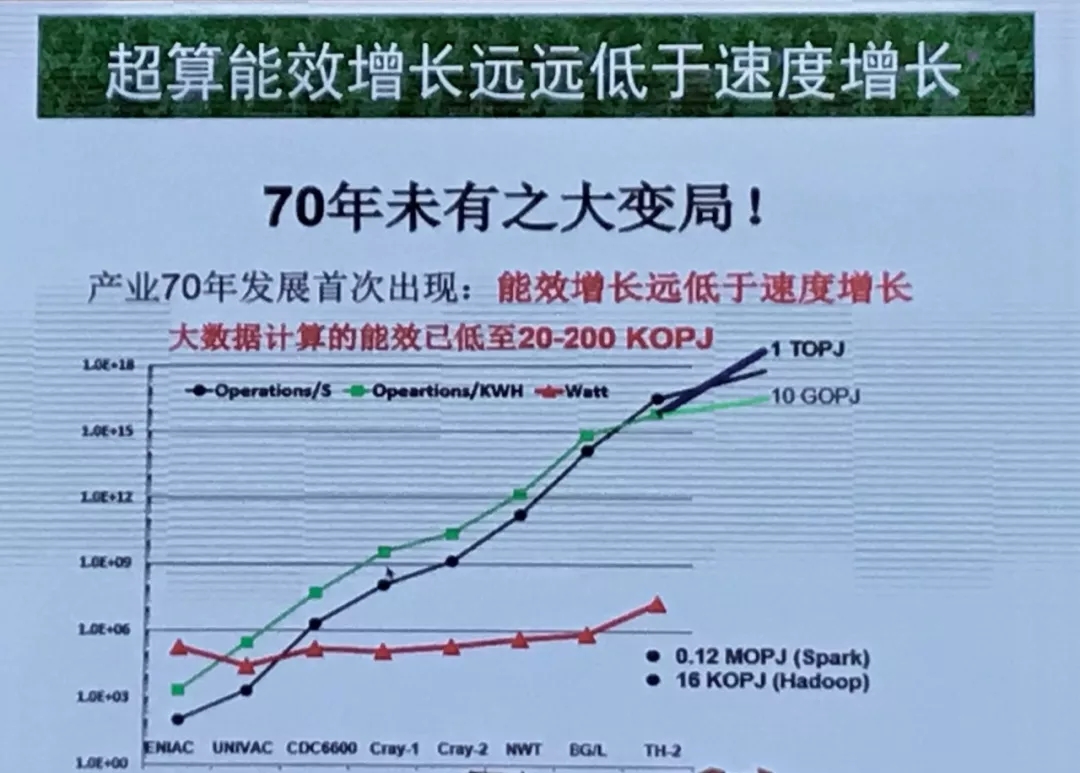
李院士将当前计算机“能效增长远低于速度增长”称为“70年未有之大变局”。来源:李院士PPT
不过,IEEE计算机学会设计自动化专业组主席、美国圣母大学计算机系教授胡晓波最近撰文指出,目前任意一种新器件都不可能解决低功耗问题,需要跨层协同。
胡晓波称,当前集成电路发展的主要矛盾是:一方面制造的特征尺寸接近物理极限使得摩尔定律即将终止,另一方面迅速增长的各种智能应用要求集成电路的计算能力更强、能耗更低。
她认为需要从底层的材料器件一直到顶层的算法应用进行整体考虑,开展跨层设计研究与优化;从深度神经网络加速器顶层架构设计需求入手,逐层分析电路层以及器件层的设计思路和面临的挑战。
第三,要研究具有”低熵”特征的未来架构。
智能计算机的本事主要体现在对付“不确定性”,而“熵”就是对不确定性的刻画。要通过全栈的系统设计应对不确定性挑战,在问题不确定、环境不确定、负载强度不确定的情况下,保障可预期的性能结果。
城市建设、交通、股市等的智能应用,都是一些动态变化、不确定性的对象,这需要从各种各样的应用中归纳出通用型强的指令系统、微体系结构、执行模型和API界面。适应不确定性负载的系统结构可能是异步执行的结构,也许要从互联网异步协议中获得启发。
第四,要重视研究领域专用系统结构(DSA)以及可重塑处理器(Elastic Processor)。
近几十年通用处理器一直胜过专用处理器,这一局面正在改变。未来大多数计算将在专用加速器上完成,而通用处理器只是配角。
DSA能实现更高性能和更高能效的原因有四:
它利用了特定领域中更有效的并行形式。
可以更高效地利用内存层次结构。
可以适度使用较低的精度。
受益于以领域特定语言(DSL)编写的目标程序。
很多加速芯片在一台计算机中,换一个应用领域切换加速芯片时间太长,就会导致性能下降,因此必须做到实时可重构。加速核的切换应在几拍时间内完成,我们称为“可重塑处理器”,这是一个新目标。
可重塑处理器使用“函数指令集”——一种体系结构适应数千种芯片,一款芯片适合上千种应用,功耗可低至0.1W数量级。目前,寒武纪芯片正在朝这个方向努力。
第五,要重视智能超算的通用性。
尽管专用化是趋势,但作为一个智能中心和超算中心,还是要本着为大众服务的目标尽量匹配更多用户的需求。
在Summit计算机交付之前,美国能源部已经成立了25个应用软件研发小组,设计能够利用E级计算机的软件。美国E级计算机研制计划(ECP计划)是否成功的指标不是Linpack性能,而是这25个应用性能的“几何平均值”,这意味着其中任何一个应用的性能都不能很差。
在应用牵引上我们应虚心地向美国同行学习。
第六,模拟计算值得重视。
传感器接受的都是模拟信息,人脑处理的也是模拟量,连续变量的模拟计算是非图灵计算。模拟计算是离散数字计算的前辈,经过60年的变迁,模拟计算可能有机会东山再起,连续变量与离散变量的混合计算将开启计算新天地。
量子计算是介于连续计算和离散计算之间的计算模式,再进一步就是连续量计算。量子计算可能会比许多人预期的进展速度更快,计算机界目前基本上没有介入,应鼓励更多的计算机学者投入到量子计算行列。
图灵机上不能表示实数(连0.1都不能精确表示)。上世纪80-90年代曾有一些学者研究实数计算,有一系列的成果。离散数据背后有一个连续数学模型,如何在计算机上反映连续的数学模型值得研究。
第七,计算存储一体化。
人类的大脑计算和存储不是分开的,不需要数据搬移,所以未来的计算机体系结构可能要改变传统的把计算和存储分开的冯•诺依曼结构。
目前实现计算存储一体化有两种方法。一种方法是Processing in memory,PIM。在阻变存储器实现神经网络计算,在存储里做深度学习,功耗可以降低20倍,速度提高50倍。美国加州大学圣塔芭芭拉分校的谢源教授在JUMP项目中承担一项研究任务(Intelligent memory and storage),就是采用PIM方法。
另一种方法是采用3D堆叠,称为Memory Rich Processor,就是在处理器周围堆叠更多的存储器件。谷歌第二代TPU放上了64G内存,带宽从第一代的30GB/s提高到600GB/s。
第八,推理驱动与数据驱动可能会交替发展。
目前的智能应用,主要是数据驱动。人工神经网络属于开普勒研究模式,而人工智能研究中的推理驱动则是继承牛顿的演绎推理模式。
1956年的“达特茅斯会议”第一次讨论人工智能,会议的经费申请报告中写的研讨会的基础是“学习以及智能的其他所有特征的方方面面,原则上都可以精确描述,从而可以制造出仿真它的机器。”这就预设了实现人工智能要走牛顿的技术路线:先精确描述智能。
这可能也是麦卡锡将这一学科命名为“人工智能”而不是“机器智能”的原因。
邱成桐先生的主张也是演绎推理模式。但智能领域也许不存在F = ma这样简洁的公式,数据驱动如何转到推理驱动需要认真探索。
第九,要重视事件驱动计算(Event Based Computing)。
大脑神经元之间的通信是神经脉冲,这是一个异步事件。而第一代和第二代人工神经网络都是基于神经脉冲的频率进行编码,没有考虑“时间”因素。未来人工神经网络应考虑“时间”因素,基于事件的信息流(事件驱动计算)可直接反映人脑工作的自然模式,这是一种新的“空间-时间模式”。
上世纪80年代Carver Mead 最先开始这一方向研究。英国的曼彻斯特大学的Steve Furber教授领导的欧盟人类脑计划(HBP)项目,也在进行事件驱动计算研究。
数据驱动(data-driving)也是一种事件驱动的异步计算,在发展智能超算中应关注数据流计算(data flow computing),特别是数据驱动执行模型。
第十,要建立智能超算新的测试基准。
长期以来,评测超级计算机的性能都采用Linpack测试程序,这是一个求解线性方程组的程序。这个程序的优点是可扩展性特别好,而且,Linpack是CPU密集应用的程序,可以测出几乎满负荷、满功耗下的计算机浮点计算性能。从这个意义上讲,Linpack是测试超级计算机可靠性和稳定性的理想程序。
但是,求解线性方程组终究只是一种应用,全面衡量超级计算机的性能需要更合适的基准(benchmark)测试程序,可惜现在还没有。由于功耗的限制,发展通用超级计算机已遇到极大的困难,近年来领域专用超级计算机成为热门研究方向,Linpack显然不适合作为领域专用计算机的测试标准。
建立统一的基准评价标准,有助于行业内的良性竞争。希望从过去的超算到大数据和人工智能有一套新的标准,有一把尺子衡量技术,将影响力从学术界延伸至产业界。

李院士提出要建立智能超算新的测试基准。来源:李院士PPT
今年6月19日,HPCWire发布了一项新的智能超算性能测试标准HAL-AI的测试记录,目前TOP500排名第一的Summit超级计算机达到445 Petaflops,比原来的HPL(即Linpack)记录148Petaflops 高出3倍。
HPL测得是双精度(64位)浮点计算速度,而HPL-AI是混合精度测试,包括适合智能应用的8位、16位、32位计算。HPL-AI特别适合核聚变、识别新分子和地震断层解释等超级计算,这些应用中大量用到GPU。
目前美国学者只是建议HPL-AI像Green 500一样,作为Linpack的补充,不是替代Linpack。中科院计算所等单位在2019年国际智能计算机大会上也提出了数据中心AI、智能超级计算机HPC AI 500 等测试标准,希望中国学者在制定智能计算机测试标准上做出更大的贡献。