深度学习算法地图
导读:本文是机器学习算法地图的下篇,系统地整理了深度学习算法,整张图的设计风格与机器学习算法地图保持一致。从去年底就开始酝酿深度学习算法地图,然而工程浩大。这张图是SIGAI算法工程师集体智慧的结晶,也是在研发SIGAI核心产品-简单易用的机器学习框架过程中的副产品。
自去年7月份SIGAI机器学习算法地图问世以来,受到了业内人士的热烈欢迎。百度云盘、TensorInfinity官网,以及纸质版已经累计邮寄、下载、发放超过5万册。这张地图有多种用法:可用作电脑桌面,让你烂熟于心;可贴在墙上,装饰你的卧室。有用户反映它有辟邪的效果,挂在墙上,过拟合、不收敛之类的问题敬而远之。更有甚者,有成功人士将其刷在办公室墙上,作为镇宅之宝。机器学习算法地图中的绝大部分算法,在SIGAI公众号某作者所著的《机器学习与应用》,清华大学出版社,雷明著中均有详细讲述。自2019年1月出版以来,已经重印4次,第二版做了大幅度优化,将于6-7月出版。欢迎大家拍砖,一起将其打造成这个时代的经典。
本文是机器学习算法地图的下篇,系统地整理了深度学习算法,整张图的设计风格与机器学习算法地图保持一致。从去年底就开始酝酿深度学习算法地图,然而工程浩大。这张图是SIGAI算法工程师集体智慧的结晶,也是在研发SIGAI核心产品-简单易用的机器学习框架过程中的副产品。由于深度学习的算法变种太多,而且处于高速发展期,因此难免会有疏漏,后续版本将不断完善与优化。本文介绍的大部分算法,在《机器学习与应用》一书中也有完整的讲述。
完整的算法地图
下面先看这张图,以观深度学习全貌:
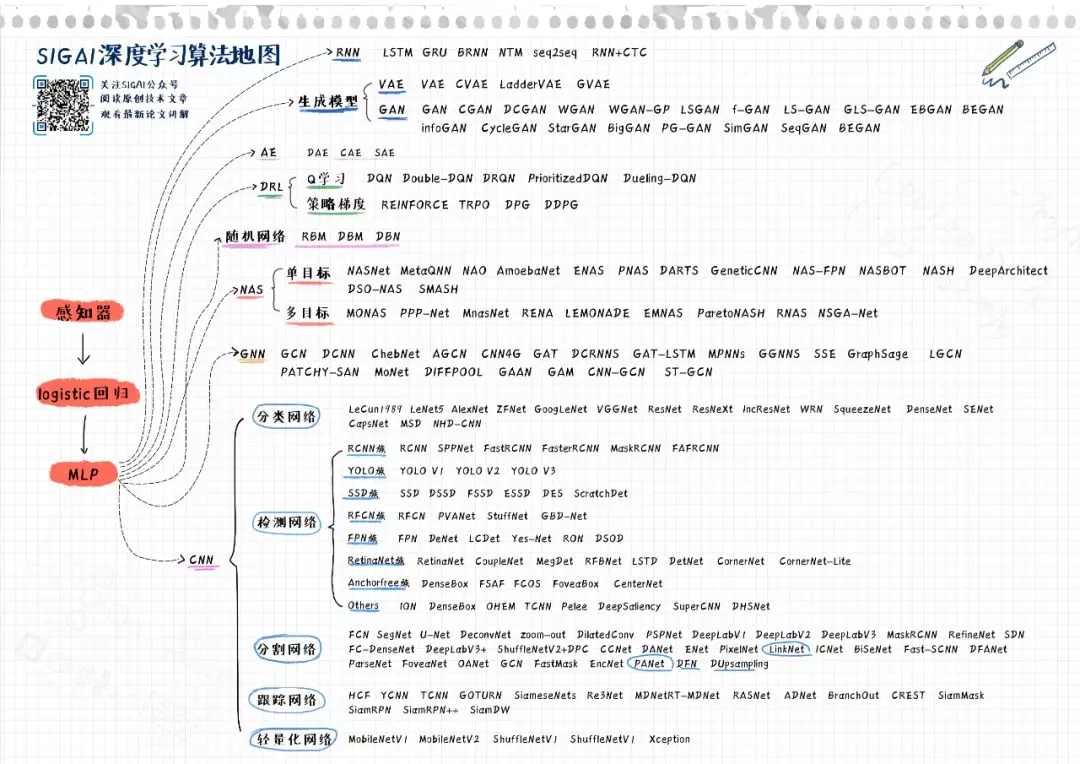
此图的清晰版本可以从SIGAI微信公众号或张量无限官网www.tensorinfinity.com下载。此图只列出了深度学习领域最重要的模型,限于篇幅以及为了简洁,那些鲜为人知的方法没有全部列出。图中体现了两条主线:
从感知器-logistic回归-多层感知器模型(MLP)到深度神经网络的发展过程。这是深度学习的完整历史。
深度神经网络的各种类型。包括卷积神经网络/CNN,循环神经网络/RNN,深度生成模型,图神经网络/GNN,深度强化学习/DRL,自动编码器/AE,随机神经网络,神经结构搜索/NAS这8个一级分支。
卷积神经网络列出了分类网络,检测网络,分割网络,跟踪网络,轻量化网络这5个二级分支。此外还有为其他应用而生的网络,如3D视觉,人脸识别,人脸检测等,在这里没有完全列出。
检测网络列出了8个分支,分别为RCNN家族,YOLO家族,SSD家族,RFCN家族,FPN家族,RetinaNet家族,Ahchor Free家族,以及其他类型的算法。需要强调的是,这里的分类并没有一个标准,你有自己的看法或对这种分类有异议是很正常的。
深度生成模型列出了2个分支,包括变分自动编码器/VAE,以及生成对抗网络GAN。除此之外,还存在其他类型的生成模型,但影响力较小,故没有列出。
深度强化学习列出了2个分支,包括基于价值函数的算法/DQN,以及直接对策略进行优化的策略梯度算法/PG。其他类型的方法没有一一列出。
神经结构搜索列出了2个分支,分别为单目标NAS以及多目标NAS。
感知器模型-神经网络的起点
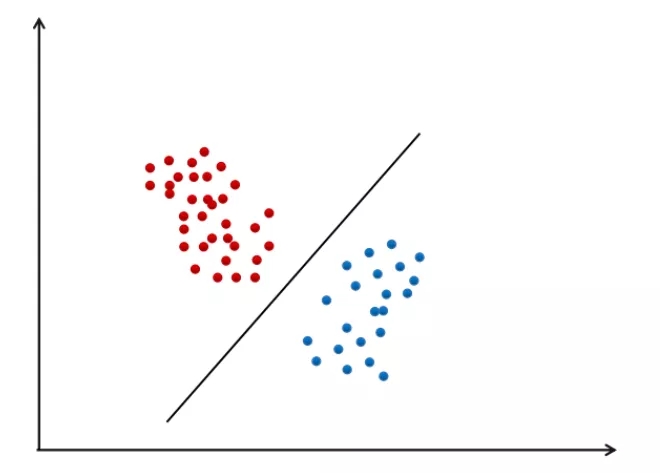
追根溯源,感知器模型可以认为是神经网络的起点,由Rosenblatt在1958年提出。这一古老的机器学习算法是一个线性分类器,用一个线性函数将各类样本分开。对于二分类问题,落在超平面一侧的样本被判定为第一类,另一边的判定为第二类。
对于二分类问题,样本标签值为+1和-1。模型的预测函数为
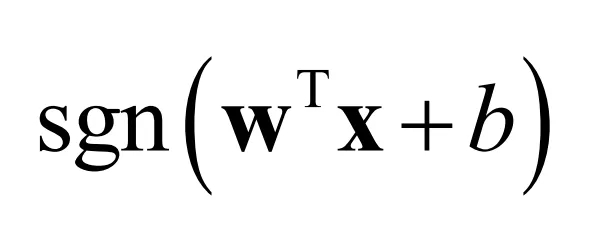
训练时的目标是最小化如下的损失函数
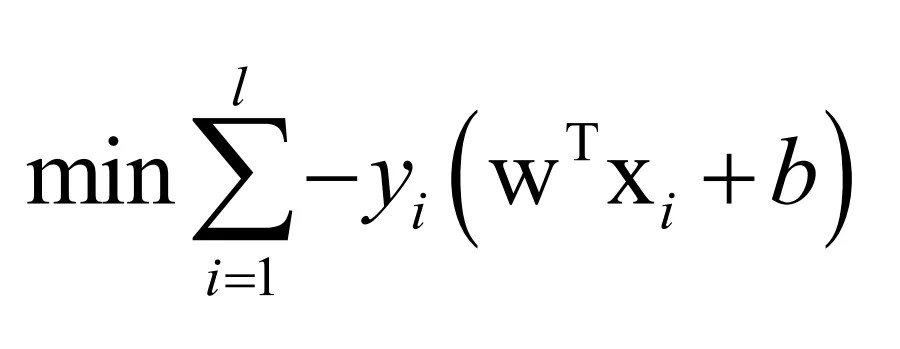
这个损失函数的意义是模型预测出来的值要和样本的标签值尽量一致,即正样本的预测值要尽量为正,负样本要为负,否则会产生一个损失值。
感知器模型过于简单,甚至不能解决经典的异或问题。

可以证明,无论用什么样的直线,都无法将上图中的两类样本分开。
logistic回归-单个神经元
logisitc回归虽然名字叫回归,但实际上是一种用于分类问题的算法,它在感知器模型的基础上加了一个logistic函数进行映射,得到区间(1, 0)类的概率值,刚好可以作为样本属于正样本的概率。这个函数定义为
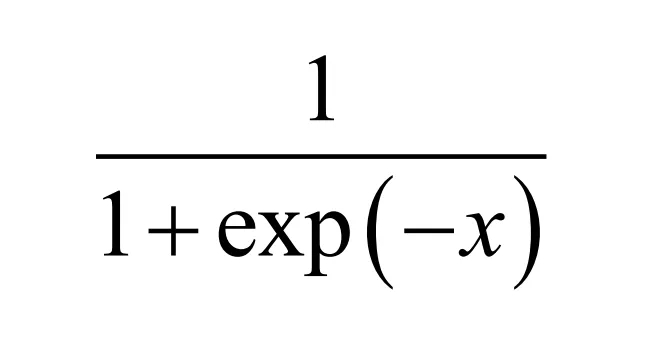
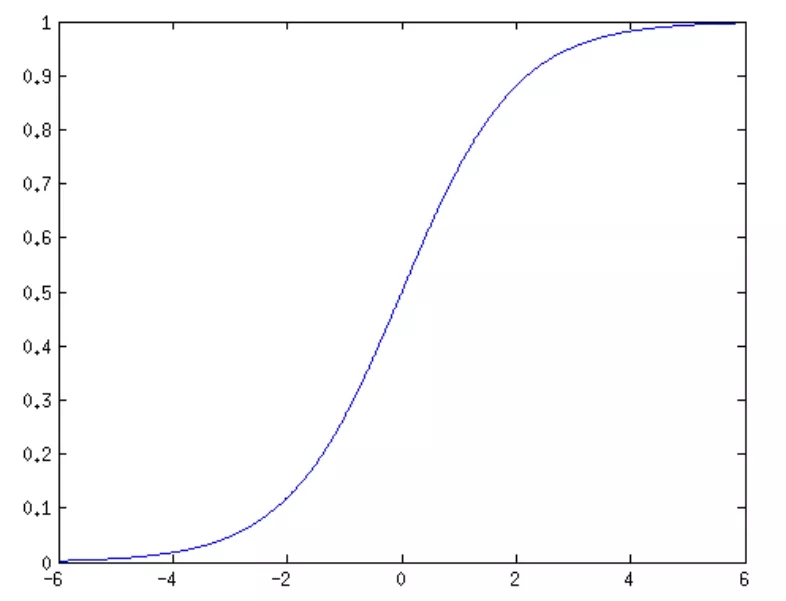
这是一个有界的单调增函数,其导数也是有界的。函数的形状是一条S型曲线,如下图所示
加上logistic函数之后,模型的预测函数为
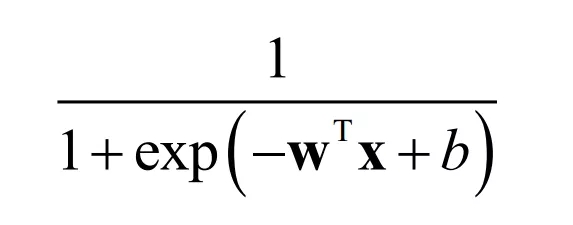
模型的参数通过最大似然估计而确定,可推导出二分类问题的交叉熵损失函数。logistic回归的具体原理在SIGAI之前的公众号文章“理解logistic回归”中已经做了详细介绍。
可以看到,logistic回归的作用类似于神经网络中的单个神经元,logistic函数即激活函数。这个函数导数的有界性为神经网络的梯度消失问题埋下了祸根。
多层感知模型(MLP)-真正意义上的神经网络
多层感知器模型(也称为全连接神经网络)是真正意义上的神经网络,可看作是logistic回归的推广。网络由输入层,输出层,以及隐含层构成。任意两个相邻的层的所有神经元之间都有连接关系。其隐含层的神经元实现的正是logistic回归的映射。
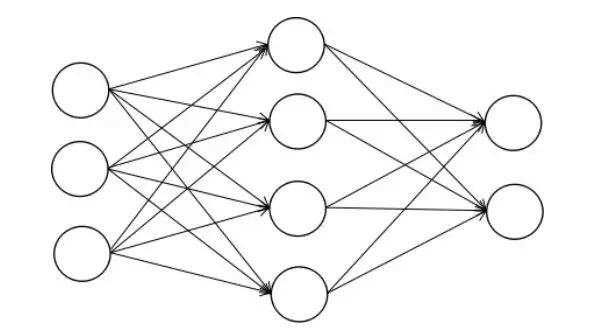
本质上看,神经网络是一个多层复合函数。万能逼近定理保证了只有一个隐含层的神经网络就可以逼近闭区间上的任意连续函数。神经网络的训练一般采用著名的反向传播算法,早在1986年就被提出。关于神经网络的原理,可以阅读SIGAI之前的公众号文章“理解神经网络的激活函数”,“反向传播算法推导-全连接神经网络”。系统的阐述可以阅读《机器学习与应用》一书。
如果将神经网络的层抽象成一个节点,则多层感知器模型是一个线性结构,每个节点最多只和其前驱节点,后续节点有连接关系。而深度学习后续的发展突破了这一限制,除循环神经网络之外,只要是无孤立节点的有向无环图,均为一个合法的神经网络结构。
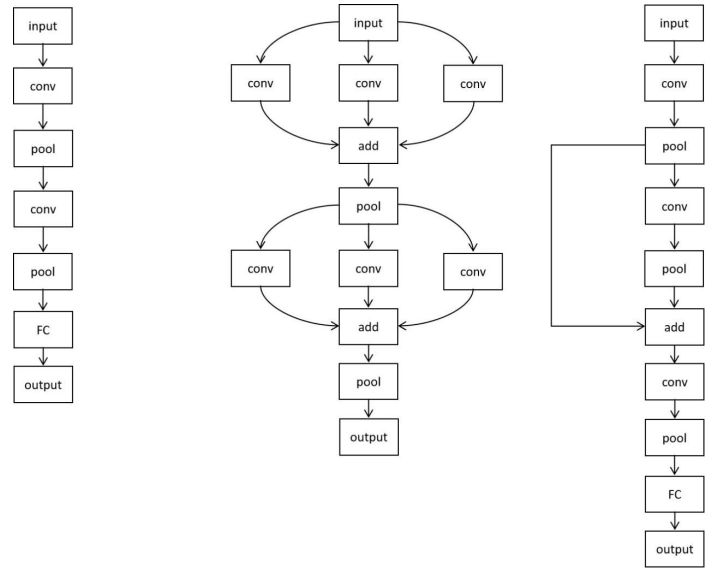
这包括多分支,跨层连接,多输入,多输出等结构。在此网络结构空间中,NAS算法可以搜索出人类未曾发现的网络结构。
深度神经网络的繁荣
神经网络自反向传播算法发明以来,并没有得到大规模成功的应用。这归咎于多个众所周知的原因。自2012年AlexNet问世以来,神经网络才真正走向了成功的应用。针对不同的应用领域,出现了多种网络结构:
1.卷积神经网络。用于空间网格结构如图像,即矩阵或张量,其输入为规则的多维数组。卷积层可以学习到这些空间结构的特征表达。
2.循环神经网络。用于序列数据,具有记忆功能,其输入为一个向量序列。成功的用于语音识别,NLP等领域。
3.深度生成模型。解决数据生成问题,即生成图像,声音这样的具有随机性的数据。其典型代表是VAE和GAN。
4.图神经网络。将神经网络的输入数据从向量、矩阵、张量扩展到了任意的图结构。可用于社交网络,电商等网状数据的挖掘。
5.深度强化学习。深度神经网络与强化学习相结合的产物,用于解决策略和控制问题,其典型代表是声名大噪的AlphaGo以及更早的打Atari游戏的DQN。
6.神经结构搜索。属于AutoML的范畴,通过机器学习算法来设计神经网络结构,从而解决只有特定领域的专业人员才能设计出性能优异的神经网络的问题,为深度学习在各个领域的普及应用带来了希望。
7.深度学习的早期模型,包括自动编码器,以及随机神经网络如RBM,现在已经很少使用了。
接下来将从这些分支进行展开,对各个领域的网络进行概括性的阐述。
卷积神经网络-最繁荣的大家族
卷积神经网络是深度神经网络中最大的家族,被成功的应用于机器视觉的各类典型问题。下图列出了各个领域的典型网络结构。卷积神经网络的反向传播算法推导可以阅读SIGAI之前的文章“反向传播算法推导-卷积神经网络”。
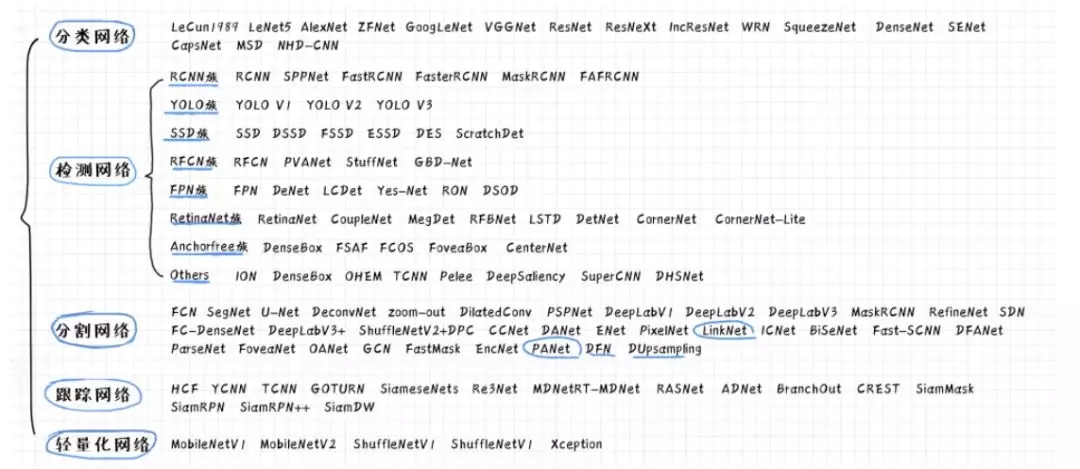
我们将CNN分为分类网络,检测网络,分割网络,跟踪网络,以及轻量化网络5大类。图像识别有这样几种类型的任务
图像分类,可抽象成将一张图像映射成一个类别标签;目标检测,可以抽象为将一张图像映射为一个目标序列,包括目标的类型,坐标,大小;图像分割,将图像映射为一张等尺寸的图像,结果图像中的一个像素为输入图像中对应像素所属物体的类别。边缘检测,轮廓检测等任务类似于图像分割。
对于卷积神经网络的综述可以阅读SIGAI之前的文章“深度卷积神经网络演化历史及结构改进脉络-40页长文全面解读”。
首先来看分类网络。自1989年LeCun提出第一个真正意义上的卷积神经网络,到今年为止,CNN已经走过了30个年头。高速发展起始于202年AlexNet,此后的GoogLeNet,ResNet,DenseNet等不停的刷新ImageNet图像分类的记录,朝着更准这条路迈进。在网络结构上,从之前单一线性结构扩展到多分支,跨层连接,以及更灵活的拓扑结构。
检测网络则是CNN中变种最多的家族。为了完成检测任务中的目标分类的定位两个子任务,出现了五花八门的网络结构。这场技术革命始于RCNN,Fastr RCNN,YOLO,SSD,mask RCNN等网络带来了令人不可思议的效果,这在人工特征+AdaBoost/SVM时代是不可想象的。目标检测算法可以阅读SIGAI之前的文章“基于深度学习的目标检测算法综述”。
分割网络也是CNN中的一个大家族,为机器视觉中的语义分割任务而生。其网络变种之多,较之检测网络丝毫不拜下风。而这一切的起点是FCN,去掉了卷积网络中全连接层,代之以卷积层这样一个神奇的结构,特别适合解决图像分割这样的密集映射
跟踪网络的要解决的核心问题是通过少量的在线训练样本学习得到被跟踪物体的检测模型。对于这一领域,大部分人可能相对陌生。
神经网络的精度越来越高,但不可避免的,模型的结构越来越复杂。这限制了深度学习的应用,如在移动端,嵌入式设备这类计算和存储资源有限的平台。轻量化网络应运而生,从MobileNet V1到后续的各种新模型,在看似简单的卷积网络结构上,研究人员硬是想出了各种新花样,将网络的规模,运行速度优化到了惊艳的程度。轻量化网络的综述可以阅读SIGAI之前的文章“轻量化神经网络综述”。
循环神经网络-序列预测的利器
与卷积神经网络相比,循环神经网络变化的花样相对较少。循环神经网络的思想起源于早期的Hopfield网络,后者当年因求解旅行商问题这一NP难问题而名噪一时。循环神经网络是神经网络大家族中唯一仅有记忆能力的结构,其输入为一个向量序列。

为了解决RNN因梯度消失问题而无法学习长期依赖的问题,早在1997年Schmidhuber就提出了LSTM这种门控结构。然而在2012年之前,这一成果都没有引起大家的注意。为了解决只能学习单向上下文信息的问题,诞生了双向RNN(pNN)。RNN+CTC与seq2seq则在语音识别以及NLP领域取得了成功,是当前的主流方法。循环神经网络的原理可以阅读SIGAI之前的文章“循环神经网络综述-语音识别与自然语言处理的利器”。
深度生成模型-以假乱真的效果
不同于用于分类,回归等任务的深度神经网络,深度生成模型的目标是生成符合某种概率分布的随机数,如图像,声音。网络的输入一般为服从均匀分布或正态分布的随机噪声数据,通过网络变换,得到服从某种潜在分布的新的随机变量数据。

这一家族中的两大成员是VAE和GAN,前者较为抽象,后者更符合人的直观思维,因此更容易理解。

GAN的思想简单而优美,取得的效果却足以以假乱真。通过生成器与判别器的对抗训练,生成器网络可以学习到复杂的概率分布,输出服从这种分布的样本数据。在过去的若干年中,GAN是学术界灌水的一个大坑。XXGAN,YYGAN层出不穷,让大家眼花缭乱。GAN的综述可以阅读SIGAI之前的文章“生成式对抗网络模型综述”。
VAE的基础是变分推断,其名为变分自动编码器,因此网络结构还是编码器-解码器结构。编码器从输入样本数据进行学习,得到某种潜在特征的分布;解码器则根据编码器学到的特征进行变换,恢复出原始的输入数据。相对于GAN,VAE要冷清不少。
深度强化学习-通往强人工智能的路
深度强化学习(DRL)是深度学习与强化学习相结合的产物,整合了深度学习的感知能力与强化学习的决策能力。其蓬勃发展的起点是2013年DeepMind公司提出的DQN,通过经验回放、随机采样等技巧,解决了训练样本之间不独立以及概率分布不固定等要命的问题。只通过观察游戏画面,就可以打游戏,甚至战胜人类的高手,在星际,魔兽等游戏上与人对抗的结果鼓舞人心,被认为是通往通用人工智能的希望之路。
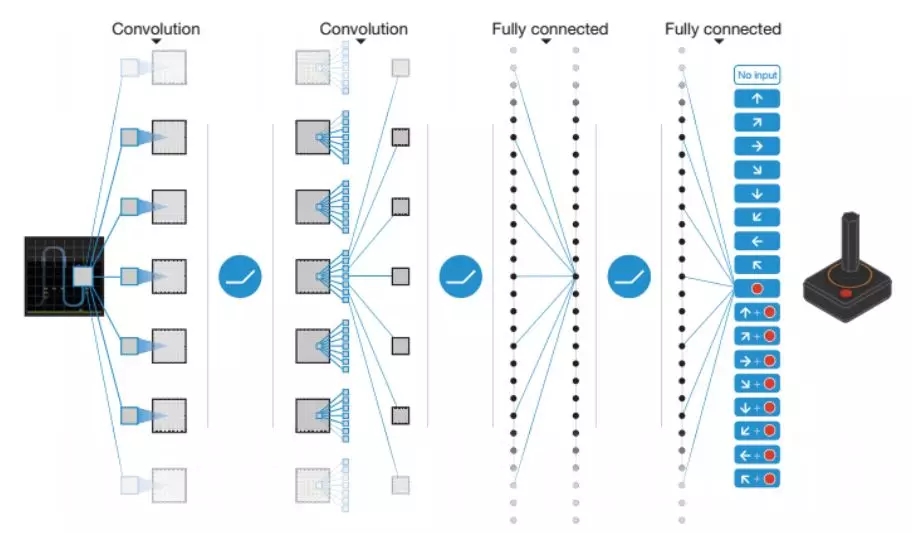
深度强化学习实现了端到端的学习,输入为图像之类的数据,输出为这种状态下要执行的动作。

在这里先将DRL分为基于价值函数的方法和直接优化策略的方法。前者的典型代表是深度Q网络,是深度神经网络与Q学习的合体,用神经网络逼近价值函数。后者这是神经网络与策略梯度算法的合体,用神经网络逼近策略函数。
图神经网络-将神经网络推广到图结构
之前的神经网络输入数据为向量,矩阵,张量以及它们的序列这样有规则结构的数据,而图神经网络则将神经网络的输入数据推广到图结构。学过离散数学或数据结构同学对图一定不会陌生,图由多个节点以及连接它们的边构成。边可能还带有权重。
不经过特殊设计,神经网络显然是不能以这样的数据作为输入的。图神经网络是这几年火起来的新方向,CNN,RNN等的可以与图进行结合。又是这几年灌水的一个大坑。

以图卷积网络/GCN为例,为了对图这样不规则的形状进行卷积,出现了两种思路,第一种是先对图计算拉普拉斯矩阵,然后再在频域上进行卷积,代表作是GCN。第二种思路则为直接对图进行卷积,即空间域卷积,典型代表是DCNNs。GNN的综述可以阅读SIGAI之前的文章“Graph Neural Network (GNN)综述”。
神经结构搜索-让神经网络的设计自动化
神经网络的设计需要大量的专业知识,成本高昂,非一般企业和个人所能承受。怎样早造出老百姓也能用的平价网络?NAS诞生了。
NAS的基本原理是给定一个搜索空间,让某种算法去设计神经网络,使得某一指标最大化,典型的指标是神经网络在验证集上的精度。求解这一问题可以采用强化学习,遗传算法,贝叶斯优化,或将问题直接连续化为一个可微的问题,然后用梯度下降法求解。这是机器学习领域近两年来又一个灌水的火爆方向。
这里我们将NAS分为单目标算法与多目标算法。前者的目标是设计出一个神经网络,使得精度等单个指标最大化。后者则要考虑多个指标,如精度与速度,保证设计出来的网络既有很高的准确率,又有很快速度,是多目标优化问题。NAS的综述可阅读SIGAI之前的文章“神经结构搜索(NAS)综述”。
自动编码器与玻尔兹曼机-深度学习早期的模型
最后来说现在已经快被遗忘的深度学习早期模型,包括自动编码器与受限玻尔兹曼机。自动编码器是一种特殊的网络结构,前面若干层为编码器,用于从输入数据提取出特征表示;后者则从特征表示重构出输入数据。在训练时,目标是使得样本的重构误差最小化。预测时则只需要编码器。自动编码器有多个变种,多层堆叠起来还可形成深度网络。

玻尔兹曼机则是一种随机性神经网络,其神经元的输出值是随机而非确定的,是神经网络家族中一个神奇的存在。将多层RBM堆叠起来使用则得到了DBM与DBN。这种模型在数学上是优美的,但现在已经很少使用。

总结
回望过去40年,神经网络如同数学、物理等学科一样,在不断的突破人类的思维限制,向着更复杂、更一般的方向迈进。而追求的目标则是更准,更快,更精简。历史选择了神经网络来扛起本轮AI复兴的大旗,它也不负众望,在感知(视觉,听觉),决策控制等问题事上挑战人类智能技术的极限。也许有一天,它会像SVM,AdaBoost等算法一样显得“过时”,但这段发展历史值得我们深思和学习。
全文PDF见:
http://www.tensorinfinity.com/paper_158.html