CVPR 2019审稿排名第一满分论文:让机器人也能“问路”的视觉语言导航新方法
导读:来自加州大学圣塔芭芭拉分校王威廉组的王鑫(第一作者)在微软研究院实习期间的研究项目以满分成绩获「审稿得分排名第一」。该论文提出的新方法结合了强化学习和自监督模仿学习两者之长,在视觉-语言导航任务上取得了显著的进步。
CVPR 2019 将于 6月15 日– 6月21日在加利福尼亚州长滩举办,会议论文录取结果也已于近日公布。其中,来自加州大学圣塔芭芭拉分校王威廉组的王鑫(第一作者)在微软研究院实习期间的研究项目以满分成绩获「审稿得分排名第一」。该论文提出的新方法结合了强化学习和自监督模仿学习两者之长,在视觉-语言导航任务上取得了显著的进步。
来源:UC Santa Barbara 计算机科学系助理教授王威廉微博。因 CVPR 2019 论文评审并非 open review,得分以及排名无法确认。
论文讲了什么
「向右转,到达厨房后再左转,转过桌子进入走廊……」使用新技术后的机器人可以根据这样的路线指令行事了,就像人类一样。
这篇论文主要解决的是视觉-语言导航(VLN)问题,即研究如何通过自然语言告诉智能体该怎么运动,智能体需要像问路者那样根据自然语言导航至目的地。因为自然语言是完整路径的指导,而智能体只能观察到当前局部视野,因此重要的是智能体需要知道当前局部视觉对应着语言指导的哪一步。为了解决视觉-语言导航中出现的各种问题,这篇论文提出结合强化学习(RL)和模仿学习(IL)的解决方案。
如下图 1 所示为 VLN 任务的示例,左侧的 Instruction 是用于指导智能体该怎么走的自然语言,除了接收指令外,智能体只能看到 Local visual 所示的局部图像视野。因为智能体并不能获取全局轨迹的俯视图,所以它只能将自然语言指令「想象」成全局的视觉轨迹,然后再根据局部视野一点点探索并导航至目标。
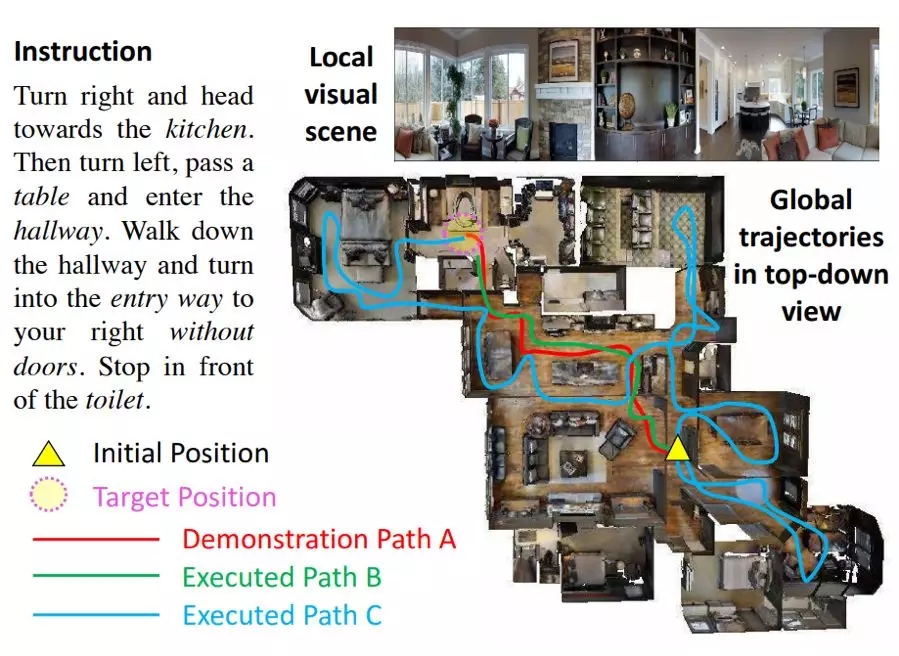
图 1:VLN 任务演示。图中展示了指令、局部视觉场景和俯视图的全局轨迹,智能体并不能获取俯视图信息。路径 A 是遵照指令的演示路径,路径 B 和 C 是智能体执行的两个不同路径。
在这篇论文中,作者主要通过增强型跨模态匹配(RCM)和自监督模仿学习(SIL)处理 VLN 任务。其中 RCM 会决定当前智能体应该关注自然语言中的哪一个子指令,以及局部视野哪个画面与之相对;同时 RCM 还会评估已走的路径到底和自然语言指令相不相匹配。而 SIL 主要是探索未见过的环境,从而模仿过去的优良经验而走向目的地。
论文:用于视觉-语言导航的增强型跨模态匹配和自监督模仿学习

地址:https://arxiv.org/abs/1811.10092
摘要:视觉-语言导航(VLN/vision-language navigation)是引导具身智能体(embodied agent)在真实三维环境中执行自然语言指令的任务。在这篇论文中,我们研究的是如何解决这一任务的三大关键难题:跨模态基础标对(cross-modal grounding)、不适定反馈(ill-posed feedback)和泛化(generalization)问题。首先,我们提出了一种全新的增强型跨模态匹配(RCM)方法,能够通过强化学习(RL)在局部和全局增强跨模态基础标对。尤其需要指出,我们使用了一个匹配度评估器(matching critic)来提供一种内部奖励,以激励指令和轨迹之间的全局匹配;我们还使用了一个推理导航器,以在局部视觉场景中执行跨模态基础标对。我们在一个 VLN 基准数据集上进行了评估,结果表明我们的 RCM 模型在 SPL 任务上显著优于已有方法(超过 10%),并实现了新的当前最佳水平。为了提升所学到的策略的泛化能力,我们进一步引入了一种自监督模仿学习(SIL)方法,可通过模仿自己过去的优良决策来探索未曾见过的环境。我们表明,SIL 可以近似得到更好更有效的策略,能极大地缩小在见过的和未见过的环境中的成功率差距(从 30.7% 到 11.7%)。
引言
近段时间来,基于视觉-语言的具身智能体受到了越来越多的关注 [32, 22, 7],原因是它们在家用机器人和个人助手等很多有趣的现实应用中都有广泛的使用。同时,通过置身于使用第一人称视觉的主动学习场景中,这样的智能体也能推进视觉和语言的基础发展。尤其值得提及的是视觉-语言导航(VLN),该任务是指通过自然语言指令引导智能体在真实环境中运动。VLN 需要深度理解语言语义和视觉感知,最重要的是要实现这两者的对齐。智能体必须推理与视觉-语言动态相关的信息,以移动到根据指令推断出的目标。
VLN 有一些独特的挑战。第一,根据视觉图像和自然语言指令进行推理可能很困难。如图 1 所示,为了到达目标点,智能体需要将指令「落地」到局部视觉场景中,还要将这些用词序列表示的指令匹配成全局时间空间中的视觉轨迹。第二,除了严格遵照专家演示之外,反馈是相当粗糙的,因为「成功」反馈仅在智能体到达目标位置时提供,而完全忽视该智能体是遵照了指令(比如图 1 中的路径 A)还是采用了一条随机路径到达目标(比如图 1 中的路径 C)。如果智能体停止的时间比应该的略早一些(比如图 1 中的路径 B),即使匹配指令的「好」路径也可能被认为是不成功的。不适定的反馈有可能会偏离最优策略学习。第三,已有的研究成果深受泛化问题之苦,使得智能体在见过的和未见过的环境中的表现会有很大差距。
在这篇论文中,我们提出结合强化学习(RL)和模仿学习(IL)的能力来解决上述难题。首先,我们引入了一种全新的增强型跨模态匹配(RCM)方法,可通过通过强化学习在局部和全局增强跨模态基础标对。尤其要指出,我们设计了一种推理导航器,可在局部视觉场景与文本指令中学习跨模态基础标对,这样能让智能体推断应该关注哪个子指令以及应该看哪里。从全局的角度看,我们为智能体配备了匹配度评估器(matching critic),可以根据由路径重建原始指令的概率来评估所执行的路径,我们称之为循环重建奖励(cycle-reconstruction reward)。局部而言,这种循环重建奖励能提供一种细粒度的内部奖励信号,可鼓励智能体更好地理解语言输入以及惩罚与指令不匹配的轨迹。举个例子,如果使用我们提出的这种奖励,则路径 B 被认为优于路径 C(见图 1)。
使用来自匹配度评估器的内部奖励和来自环境的外部奖励进行训练,推理导航器可以学习将自然语言指令「落地」到局部空间视觉场景和全局时间视觉轨迹上。我们的 RCM 模型在 Room-to-Room(R2R)数据集上显著优于已有的方法并实现了新的当前最佳表现。
我们的实验结果表明模型在见过的和未见过的环境中的表现差距很大。为了缩小这一差距,我们提出了一种有效的解决方案,即使用自监督来探索环境。这项技术很有价值,因为它可以促进终身学习以及对新环境的适应。举个例子,家用机器人可以探索其到达的新家庭,并通过学习之前的经历迭代式地提升导航策略。受这一事实的启发,我们引入了一种自监督模仿学习(SIL)方法,以探索不含有标注数据的未见过的环境。智能体可以学习模仿自己过去的优良经历。具体而言,在我们的框架中,导航器会执行多次 roll-out,其中优良的轨迹(由匹配度评估器确定)会被保存在重放缓冲区中,之后导航器会将其用于模仿。通过这种方式,导航器可以近似其最佳行为,进而得到更优的策略。总结起来,我们有四大贡献:
我们提出了一种全新的增强型跨模态匹配(RCM)框架,能让强化学习同时使用外部奖励和内部奖励;其中我们引入了一种循环重建奖励作为内部奖励,以强制执行语言指令和智能体轨迹之间的全局匹配。
我们的推理导航器可学习跨模态的背景,基于轨迹历史、文本背景和视觉背景来做决策。
实验表明 RCM 能在 R2R 数据集上达到新的当前最佳表现,在 VLN Challenge 的 SPL 方面(该任务最可靠的指标)也优于之前的最佳方法,排名第一。
此外,我们引入了一种自监督模仿学习(SIL)方法,可通过自监督来探索未曾见过的环境;我们在 R2R 数据集上验证了其有效性和效率。
增强型跨模态匹配(RCM)
这里我们研究的是一种具身智能体,它们需要学习通过遵循自然语言指令而在真实的室内环境中导航。如图 2 所示,RCM 框架主要由两个模块构成:推理导航器和匹配度评估器。给定起始状态和自然语言指令(一个词序列),推理导航器要学习执行一个动作序列,这些序列会生成一个轨迹,以便到达由指令指示的目标位置。导航器在智能体执行动作过程中会与环境交互以及感知新的视觉状态。为了提升泛化能力以及增强策略学习,我们引入了两个奖励函数:一个由环境提供的外部奖励和一个源自我们的匹配度评估器的内部奖励。其中外部奖励度量的是每个动作的成功信号和导航误差,内部奖励度量的是语言指令与导航器轨迹之间的对齐情况。
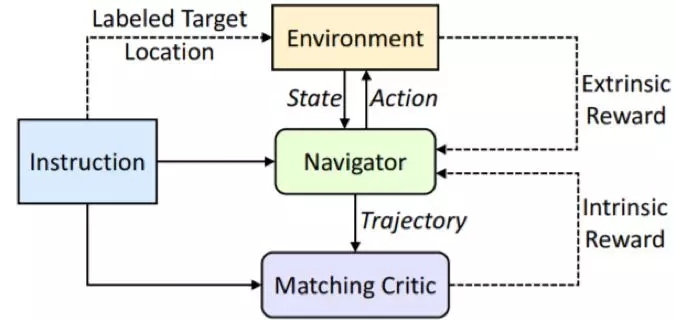
图 2:RCM 框架概况
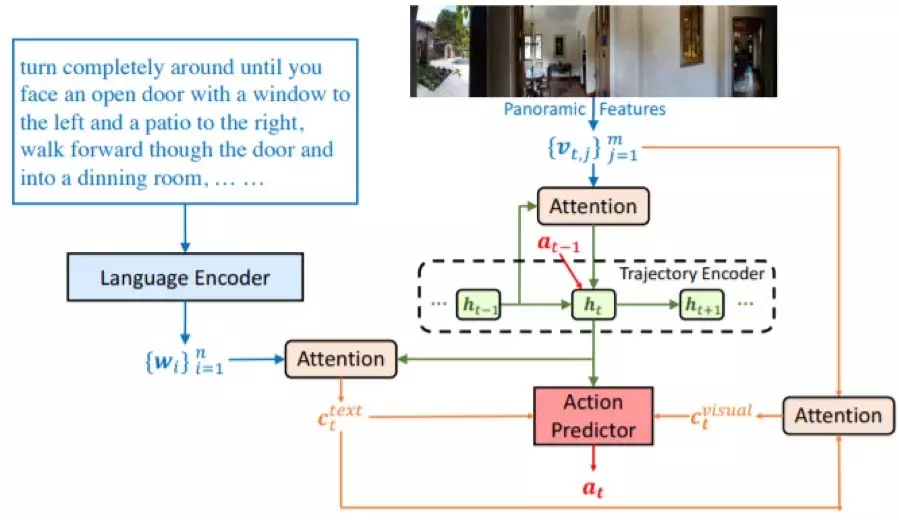
图 3:在步骤 t 的跨模态推理导航器
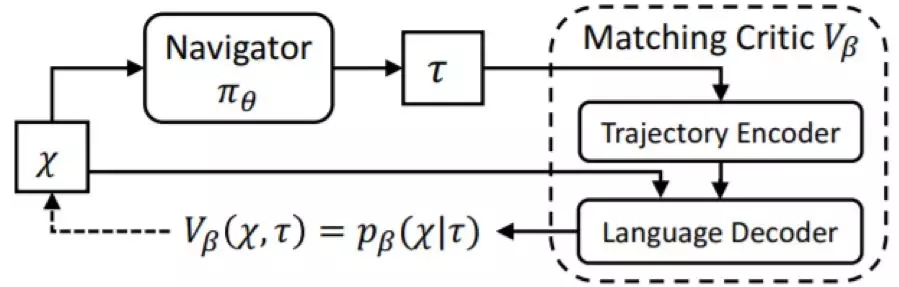
图 4:提供循环重建内部奖励的跨模态匹配度评估器
自监督模仿学习(SIL)
这一节将介绍可用于通用的视觉-语言导航任务的有效的 RCM 方法,其标准设置是在已见过的环境中训练智能体,然后在未探索过的未见过的环境中测试它。在这一节,我们会讨论一种不同的设置,即允许智能体在没有基本真值演示的条件下探索未见过的环境。这种做法是有实际价值的,因为这有助于终身学习和对新环境的适应。
为此,我们提出了一种自监督模仿学习(SIL)方法,可模仿智能体自己过去的优良决策。如图 5 所示,给定一个无相应的演示的自然语言指令和基本真值的目标位置,导航器会得到一组可能的轨迹并将其中最佳的轨迹(由匹配度评估器确定)保存到重放缓冲区中。
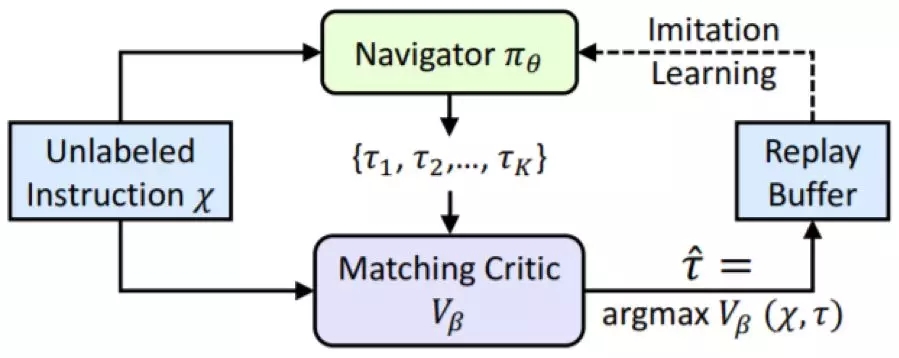
图 5:用于探索无标注数据的 SIL
匹配度评估器会使用之前介绍的循环重建奖励来评估轨迹。然后通过利用重放缓冲区中的优良轨迹,智能体确实能使用自监督优化目标。这里的目标位置是未知的,因此没有来自环境的监督。
与匹配度评估器配对后,SIL 方法可与多种学习方法结合,然后通过模仿自己之前的最佳表现来近似得到更优的策略。
实验和分析
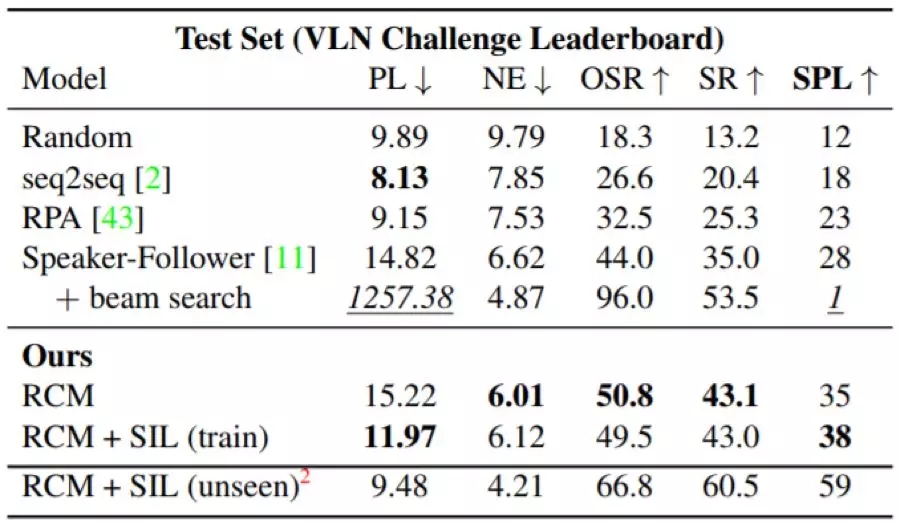
表 1:在 R2R 测试集上的结果比较。我们的 RCM 模型显著优于 SOTA 方法,尤其是在 SPL 上(SPL 是导航任务的主要指标)。此外,使用 SIL 模仿在训练集上的自己可以进一步提升其效率:路径长度缩短了 3.25m。注意使用波束搜索(beam search)时,智能体在测试时间执行了 K 个轨迹并选择了最有信心的轨迹作为最终结果,这得到了一个非常长的路径并受到了 SPL 的极大惩罚。
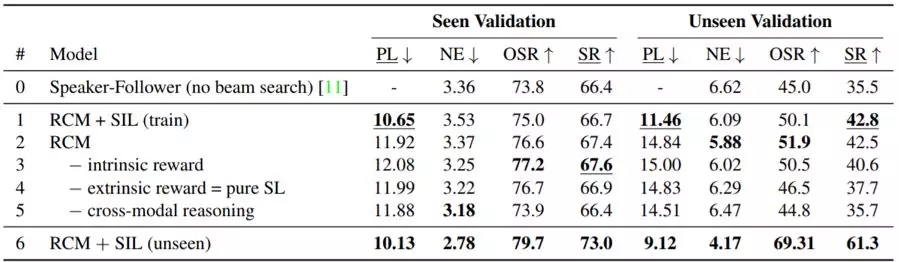
表 2:在见过的和未见过的验证集上的 ablation 研究。我们报告了没有波束搜索的 speaker-follower 模型的表现作为基准。第 1-5 行展示了通过从最终模型连续移除每个单个组件来展示其影响。第 6 行展示了 SIL 在使用自监督探索未见过的环境的结果。
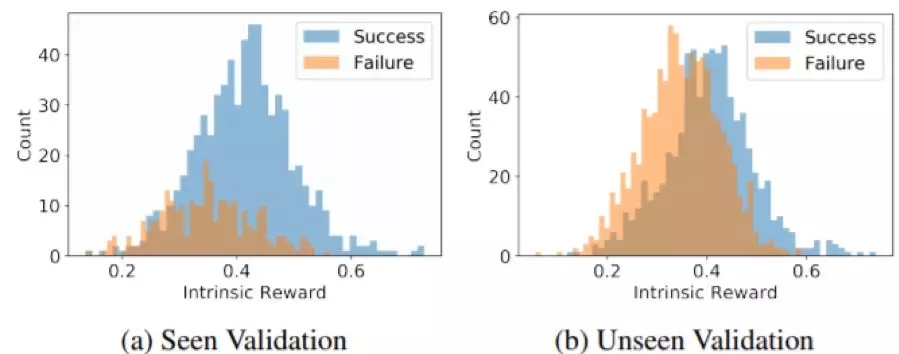
图 6:在见过的和未见过的验证集上的内部奖励的可视化

图 7:来自未见过的验证集的定性示例,(a)是一个成功案例,(b)一个失败案例
总结
我们在这篇论文中提出了两种全新方法 RCM 和 SIL,从而结合了强化学习和自监督模仿学习两者的优势来解决视觉-语言导航任务。不管是在标准测试场景中,还是在终身学习场景中,实验结果都表明了我们方法的有效性和效率。此外,我们的方法在未见过的环境中的泛化能力也很强。请注意,我们提出的学习框架是模块化的,而且与具体模型无关,这让我们可以分别各自改进各个组件。我们还相信这些方法可以轻松泛化用于其它任务。